Not so serverless Neptune
With the launch of Amazon Neptune Serverless, have we strayed so far from the purest definition of serverless that there is no going back?

Several years ago I wrote a post asking people to stop calling everything serverless. I even gave a keynote at Serverless Days Milan the following year pleading the same message. My contention was quite simple: "when everything's serverless, nothing will be."
Back then, "serverless" was still relatively new, and the possibilities were seemingly endless. Sure, there were a few people starting to mislabel things, and of course, haters were gonna hate, but for the most part, the argument was less about the nuances of the technology and more about the "nature" of serverless and the serverless-first mindset. But then something changed.
What started as a few basic principles of "serverlessness" slowly morphed into something that seemed less serverless. For those of you that don't remember, AWS initially pitched the four main benefits of serverless as (1) No server management, (2) Flexible scaling, (3) High availability, and (4) No idle capacity.
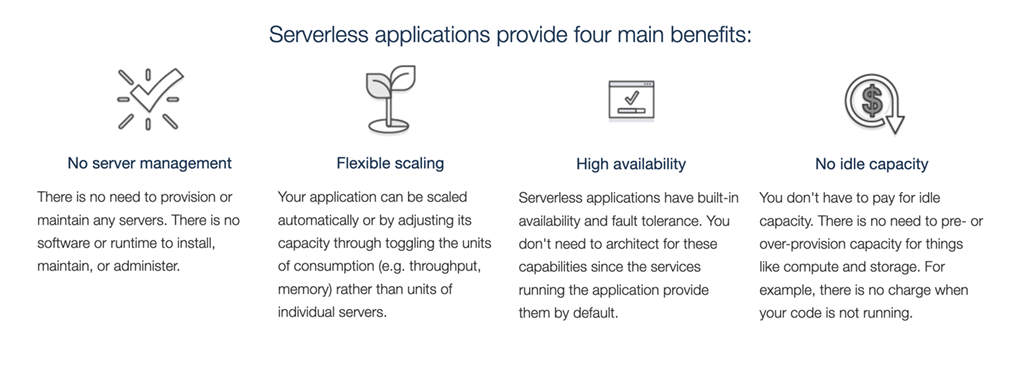
As the screenshot above shows, "No idle capacity" meant:
"You don't have to pay for idle capacity. There is no need to pre- or over-provision capacity for things like compute and storage. For example, there is no charge when your code is not running."
A year later, serverless suddenly only had THREE main benefits. I bet you can guess which main benefit didn't make the new list. Now, there are plenty of reasons for this. The timing of the Aurora Serverless v1 launch was right around then, and even though v1 could actually scale to zero, the idle capacity language wouldn't have held up.

Then, all of a sudden, right before re:Invent 2018, it had FOUR again. But that fourth benefit is now "PAY FOR VALUE", which means:
Pay for consistent throughput or execution duration rather than by server unit.

Just a few days later they announced Amazon DynamoDB On-Demand where you only pay for what you use (plus storage). All of this made sense, and while perhaps that dream of "no idle capacity" had slipped away, I was willing to make the tradeoff for all the added benefits.
The problem is, it didn't stop there. As the old adage goes, "if you give a mouse a cookie, he's going to ask for a glass of milk." Once we accepted that tradeoff, the serverless community collectively gave AWS and others an entire dairy farm.
We then got "serverless containers", Provisioned Concurrency, RDS Proxy, and more. Aurora Serverless v2 came out and practically no one accepted that to be "serverless". Now we have AWS Neptune Serverless that, forget about scaling to zero, costs over $290 USD per month to run at its lowest capacity. And no, the free tier doesn't count.
So, have we strayed so far from the purest definition of serverless that there is no going back? Or is this just what "serverless" is now? I hate to be the bearer of bad news, but somewhere along the way our compass broke, and we've strayed quite a ways off the path to the promise land. Then again, maybe it never existed in the first place?