Stop Calling Everything Serverless!
"Serverless" isn't just a buzzword, but rather something important to the future of application development. This post explores the term and offers up my thoughts on its meaning.
I've been building serverless applications since AWS Lambda went GA in early 2015. I'm not saying that makes me an expert on the subject, but as I've watched the ecosystem mature and the community expand, I have formed some opinions around what it means exactly to be "serverless." I often see tweets or articles that talk about serverless in a way that's, let's say, incompatible with my interpretation. This sometimes makes my blood boil, because I believe that "serverless" isn't a buzzword, and that it actually stands for something important.
I'm sure that many people believe that this is just a semantic argument, but I disagree. When we refer to something as being "serverless", there should be an agreed upon understanding of not only what that means, but also what it empowers you to do. If we continue to let marketers hijack the term, then it will become a buzzword with absolutely no discernible meaning whatsoever. In this post, we'll look at how some leaders in the serverless space have defined it, I'll add some of my thoughts, and then offer my own definition at the end.
This post is really long, for which I apologize. Sometimes I get into rant mode and it's hard for me to stop.

Serverless as a compute model
There are a lot of definitions of the term serverless out there, many of which focus on the execution model itself. Let's start with Wikipedia's definition.
Serverless computing is a cloud-computing execution model in which the cloud provider acts as the server, dynamically managing the allocation of machine resources. Pricing is based on the actual amount of resources consumed by an application, rather than on pre-purchased units of capacity. It is a form of utility computing. ~ Wikipedia
This is a good start. Part of it certainly seems like a form of utility computing, which makes it attractive from a pricing standpoint, but this definition is quite broad. Lots of SaaS companies work off of this model. Twilio, SendGrid, Stripe and others all meet this criteria since they all charge based on the "amount of resources consumed." Taking the term serverless and just applying it to metered SaaS products doesn't make sense to me.
How about Amazon Web Services, the leaders in serverless tech? Here's how they define it.
Serverless allows you to build and run applications and services without thinking about servers. It eliminates infrastructure management tasks such as server or cluster provisioning, patching, operating system maintenance, and capacity provisioning. You can build them for nearly any type of application or backend service, and everything required to run and scale your application with high availability is handled for you. ~ Amazon Web Services
Okay, same idea, but they expand it to include "high availability" as one of the criteria. They also communicate some of the benefits (eliminating server maintenance and management tasks), which hints at the much longer term benefit of reducing operational responsibilities. AWS goes on to outline the additional benefit of "pay for value." This used to be "never pay for idle", but as AWS had added more products and services into their suite of "serverless" offerings, some of these things are metered differently. Many of them require you to pay for the service whether you're using it or not.
So if serverless now includes services that charge you even if you're not using them, does that mean that SaaS products like Salesforce, or Jira, or even Gmail are now included in the definition? Even adding the "high availability" requirement wouldn't exclude them. This makes even less sense.
Serverless as an architectural pattern
Both of these definitions seem to focus quite a bit on the compute aspect of serverless, maybe Tom McLaughlin's definition would be a bit more helpful.
Serverless is a cloud systems architecture that involves no servers, virtual machines, or containers to provision or manage. Yes, these still exist underneath the running application but their presence is abstracted away from the developer or operator of the serverless application. This abstraction allows for greater effort and emphasis higher up the technical stack as well as the software value chain. ~ ServerlessOps
So beyond just compute, this expands the term to say that serverless is also an architectural choice that shifts the focus of cloud application development to software value creation instead of undifferentiated heavy lifting. I think the AWS definition was trying to make this point too, but Tom's definition is more direct. Now if we think of it as an architectural choice, then it must logically go beyond the existence of a single standalone service.
In order to benefit the software value chain, one must conclude that some code must exist to take advantage of the services supported by the underlying compute model. Simon Wardley put it like this:
Roughly speaking it's an event driven, utility based, stateless, code execution environment in which you write code and consume services. A boundary condition is "write code" i.e. any lower than this and it's not serverless. ~ Simon Wardley
X : How do you define serverless?
— Simon Wardley (@swardley) December 14, 2018
Me : Roughly speaking it's an event driven, utility based, stateless, code execution environment in which you write code and consume services. A boundary condition is "write code" i.e. any lower than this and it's not serverless.
We have now introduced the concept of "glue", or code that stitches together multiple services. But Simon is very clear that writing code is the lower boundary here. This essentially means that anything requiring management of the compute layer, negates the underlying concept of serverless. He goes on to say, "If you're diving into containers, you're diving out of the serverless world." So how can things such as Knative and OpenFaaS be considered serverless? And perhaps this is his point (and my gut feeling), they're not. Or at least they're not if you are responsible for them. If a cloud or other service provider was to own this type of infrastructure and offer it as a service, then using their FaaS service as glue would likely not violate this condition.
Serverless as a mindset
Now we have an architectural pattern that utilizes a compute model that abstracts away infrastructure management, allowing developers to focus primarily on business logic by (at most) writing code that consumes other services. This seems like it is getting closer, but it's still missing something. Let's get some insight from Paul Johnston:
Serverless is about understanding when not to create technology. Creating anything leads to technical debt. Serverless is about removing complexity by allowing the services that others provide to provide the complexity for you. ~ Paul Johnston
This goes well beyond an architectural pattern or a compute model. This presents serverless as a mindset. A way to look at how we solve problems by leveraging existing resources and not recreating the wheel. It's the ultimate implementation of the DRY principle (Don't Repeat Yourself), which applies to both infrastructure and business logic. I like this line of thinking, but now we've overloaded the term, and we're not even done yet.
Serverless as an operational construct
At re:Invent, AWS introduced this concept of serverless being an "operational construct." Don't Google it, because you won't find a definition of the term. What they mean is that the amount of operations required is a leading indicator as to how "serverless" something is.
Kelsey Hightower cleverly pointed out in a tweet that "If Serverless is an operational construct, does that mean my on-prem stack is Serverless as long as someone else, not me, is doing all the ops work?" While this is a bit tongue-in-cheek, it does complicate the definition.
If Serverless is an operational construct, does that mean my on-prem stack is Serverless as long as someone else, not me, is doing all the ops work? pic.twitter.com/yGsOY51qDZ
— Kelsey Hightower (@kelseyhightower) December 8, 2018
If we use the amount of operations required to measure the "serverlessness" of something, then we've now expanded the original broad definition that AWS originally set out. Now everything can be "sort of" serverless, it just depends on your level of effort required to maintain the underlying infrastructure.
Serverless as a Spectrum
Ben Kehoe referred to "serverless as a spectrum" and makes a number of great points about what serverless is and what it is not. He refers to three things that drive the "serverlessness" of something:
- Service-full + ephemeral compute
- Tighter correspondence between resources used and resources billed
- Smaller and more abstracted control plane
He also makes the point that public cloud and on-prem FaaS can both be serverless, it's just a matter of perspective. I think this is possible, so long as the implementation supports the elasticity required and the teams building the apps are following serverless principles. However, I think that's a semantic argument. But like the "operational construct", this definition further complicates our understanding of the term. While "service-full + ephemeral compute" certainly fits our execution model, architectural, and mindset criteria, we are still using it as a measuring stick, not an absolute.
Erik Peterson at CloudZero expanded on the topic and actually put these services on a spectrum. This approach also seems to use the amount of operations to determine the "serverlessness" of something, but it is meant to be used from an adoption perspective, giving one the ability to measure how "serverless" your company is.
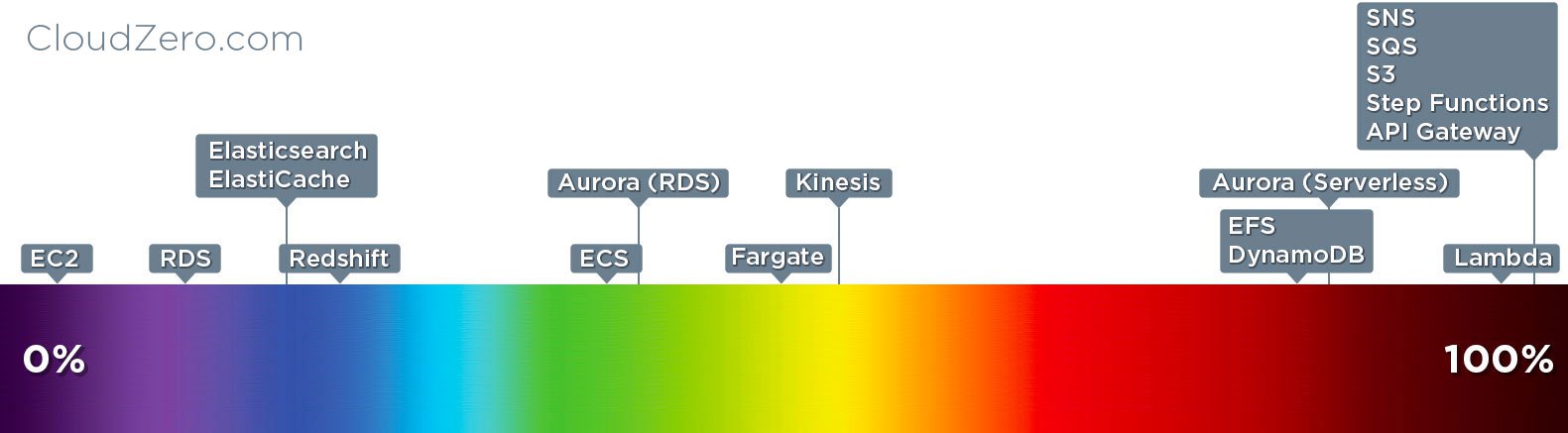
I think AWS's operational construct, and Ben and Erik's serverless spectrum, are good ways to evaluate and classify services from an operations perspective. But as I said before, this allows the term to be broadly used to describe pretty much any service.
Serverless as a cultural shift
If you thought we were overloading the term before, how about now? We need to ask ourselves how can serverless be a compute execution model, an architectural pattern, a mindset, an operational construct and a spectrum all at the same time? Perhaps we are convoluting it by focusing too much on the technology piece. Paul Johnston had some more thoughts on that:
Serverless is a culture shift. It's not a technology choice that you can make between provide X or provider Y… So when someone talks about serverless and focuses on the technology rather than practices or principles, you are probably listening to the wrong person. ~ Paul Johnston
I mostly agree with this, because I do believe that the very abstraction of the technology is one of the key tenets of what makes something serverless. However, there must be some minimum requirements from providers, right? Otherwise your application might not have the elasticity and scalability of a true serverless system. He goes on to say:
All of this leads me to the conclusion that serverless isn't so much about technology but about culture inspired by the technology that has been created for us. ~ Paul Johnston
This is very much in line with my thinking on the subject. Embracing the principles of simplicity, code minimalism, managed services, reusability, and focus on just business logic that makes your company special, is a very powerful approach to modern software (and business) development. The "serverlessness" of an underlying component might not be all that important, as long as you account for it.
Serverless as just a buzzword
You may argue that the serverless mindset isn't anything particularly novel. In fact, developers have been taking advantage of open source and commercial software for decades. Plus the DRY principle, along with abstraction, inheritance, polymorphism and encapsulation, have long been part of a programmer's ethos. You may even think that the serverless compute model isn't really new either. We've had shared commercial hosting services for over 25 years now. I actually read a tweet that likened serverless to a "cgi-bin" (remember those?) on an old web server. But these naïve comparisons show a complete lack of understanding of how modern cloud infrastructures work.
What makes cloud computing so different from the hosting companies of days gone by, is the elasticity, redundancy, and scale that its predecessors could only dream of. A single datacenter does not a cloud make. The modern cloud consists of hundreds of datacenters, edge locations, and interconnections that share massive pools of resources to provide trillions of compute cycles. This gave way to rapidly provisioning virtual machines, meaning companies could scale their compute within minutes instead of waiting for a new shipment from Dell.
As cloud providers began to understand the use cases better, they added things like elastic load balancers, auto-scaling, and automation to make scaling easier and on-demand. When they saw that users were hosting databases and other software on virtual machines, they started creating managed services that handled things like maintenance, replication, and backups for you. But even with all these advancements, there was still one constant: you needed to run your application code on a server somewhere. So even if you were taking advantage of all of these managed services, you still needed to provision, patch, monitor, and maintain virtual machines connected to a file system that had your code running on it.
But we were all building for scale, so we often had tens if not hundreds of servers running our applications. Often we would be maintaining multiple fleets of servers that ran different parts of our applications. This often made rolling out new versions a massive pain. Even when we automated it, the process of disconnecting machines from the load balancer, updating the code, then reconnecting, was a gut wrenching experience. Don't even ask me about rollbacks and split-brain scenarios. Deployments, however, weren't the real problem, under utilization was.
We now had a fleet of powerful machines running relatively small applications that barely moved the needle with regard to utilization of resources. So some really smart people came up with the idea to run multiple virtual machines within another virtual machine, which they named containers. Containers were brilliant for a number of reasons. One, they ran as isolated environments. This meant that several containers could be running on the same host without worrying about cross-contamination of memory and the file system. Two, they included their own dependencies, allowing you to install just the software and configurations needed for the application code running on that container. And three, they were highly portable. This meant that as long as the underlying system was compatible, you could move containers between hosts fairly easily. Now we could host a boat load of containers on each virtual machine and get rid of that pesky underutilization problem. Easy right? Not exactly.
Now we created a bigger problem. Instead of managing 50 servers, we were now responsible for hundreds or thousands of containers on top of that. So along came container orchestration. Maybe you've heard of Kubernetes? But does this solve the latest problem? Sort of. Once you've got your orchestration management system all setup and deployed, ongoing maintenance is pretty straightforward, but you're still maintaining the operating systems on each container and the underlying servers. AWS has created some services (ECS and EKS) to make this easier for you. But we're now a long way from a developer simply FTPing a Perl script up to their cgi-bin. And this is perhaps where things come full circle. Something needed to be done to abstract away all that complexity. And it's not just a new buzzword.
Serverless as a modern day cgi-bin
There was an elegance to how we built and deployed web software in the 1990s and early 2000s. You wrote a script that did something, uploaded it to your hosting provider, and it just magically worked. But somewhere along the way we sacrificed simplicity for scalability. We either decomposed our applications into smaller and smaller pieces, or we simply ran as many horizontal copies of it as needed to serve our audience. We often tried to fit square pegs into round holes, like somehow thinking that relational databases would scale just as easily as our applications would.
And with every new challenge we faced, we found more and more complex methods to solve our current problems. The people who understood these methods became known as "operations" people, and were the witches and wizards that cast spells and conjured Chef scripts that made our code and infrastructures run. But then our applications and their stakeholders got greedy, and we wanted more from our systems. Faster deployments, more 9s, lower costs. "Tear down this wall," they shouted, so we created a thing called DevOps that brought developers closer to the infrastructure running their code, and the operations team closer to the code they needed to support.
This is all a bit overwhelming, but it is a common pattern that seems to repeat itself everywhere. You take something simple, elegant, and straightforward, and you create layers of complexity until the learning curve becomes so steep that the barrier to entry is too high for most to summit. And this is why serverless is so fricken important. Serverless takes the last decade of cloud complexity and reduces it down to a developer simply uploading their code to a metaphorical cgi-bin.
When I read that tweet about serverless being like an old school cgi-bin, I know that it was not meant as an endorsement. But thinking about it now, it might be the perfect way to describe it. You write a script, upload it your cloud provider, and it magically works... at Internet-scale. No servers to manage or containers to orchestrate. No crystal balls required for capacity planning or automation scripts to trigger auto-scaling groups. Just a developer, their code, and few limits to their imagination.
As I said earlier, functions (or FaaS, functions-as-a-service) are the glue that makes stitching together these other building blocks possible. This introduces a new kind of reusability and flexibility that is only possible with a serverless approach.
Serverless is a methodology
We reviewed the thoughts of many smart people in this post. And when we combine all of them, we ultimately come up with a very long and convoluted definition that isn't very helpful or meaningful. There are parts of it that resonate with me, and I can certainly understand the reasoning behind their thoughts.
Below are my opinions on what serverless is and what it is not. For those of you that I've disagreed with, I mean no disrespect. I simply think that the term "serverless" has been a victim of marketers and has lost its true essence. So without further ado, here are my humble thoughts:
Serverless is NOT an execution model
While FaaS introduced us to the per execution billing concept, ultimately how our code gets executed, how our datastore scales, or how our message brokers handle delivery, has all been abstracted away into separate managed services. Many of these services are utility-based, but I agree with AWS that it is more about paying for value than it is about "never paying for idle." I would say that FaaS is an execution model, and is a key component to serverless architectures, but serverless is not itself an execution model.
Managed services are NOT serverless
I do not believe that services like DynamoDB, Aurora Serverless, SQS, or even Lambda are "serverless." Not to sound like that annoying guy who keeps chanting that "there are still servers in serverless", but these services run on servers that must be maintained by the cloud provider. You can (and should) utilize these types of services as part of your serverless architecture, as the underlying server management is done for you. Just to cover all my bases here, I will say that it might be possible for a managed service to technically be serverless if the managed service provider built their service on top of another service provider's managed services. Think about that. 🤔
Serverless is NOT an operational construct or a spectrum
The "serverlessness" of an individual component is largely irrelevant in my opinion. If I have to manage containers, or be responsible for scaling my read replicas in an RDS cluster, those parts of my architecture are simply NOT serverless. I think this is pretty black and white and quite simple to "know it when you see it." For example, if I built an architecture that consisted of Lambda functions, DynamoDB, SQS, SNS, S3, and API Gateway, I know that my architecture is 100% serverless. If I introduce Fargate into the mix, then I've added operational complexity that requires a low level of server maintenance. I'm no longer 100% serverless, not because Fargate is on the spectrum, but because it violates a core tenet of the serverless mindset. Also, tweaking a few settings here and there, or requiring significant configuration to setup a service, certainly adds complexity, but the lack of ongoing operations is the distinction.
Serverless is NOT a technology
Fargate introducing operational complexity is different than something like Aurora Serverless introducing potential scaling problems. I do not believe that utilizing services that are unable to reach Internet-scale, somehow makes your architecture less serverless. There are absolutely zero services out there that could scale infinitely if the need ever arose. That's not to say that some aren't better than others, but ultimately we must assume that systems and services will eventually fail. This means that serverless architectures must plan for failure and be highly resilient.
Serverless is ultimately a methodology
Whether you call it a culture, or a mindset, or even a set of architectural best practices and principles, serverless, IMO, is a methodology for planning, building, and deploying software in a way that maximizes value by minimizing undifferentiated heavy lifting. It touches everything up and down the value chain, not only affecting how engineers approach development, but also influencing product strategy, design, budgeting, resource planning and much more. I also believe that applications built using the serverless methodology are themselves "serverless", but that is a distinction that is independent of the provider or the underlying technology and services being used.
In Conclusion
I know that this post was painfully long, and that many of you will likely disagree with my interpretation. But I am extremely passionate about serverless because of the possibilities it opens up for developers and organizations of all sizes. The simplicity of the FaaS model, along with embracing a service-full approach, gives you the ability to deploy applications without worrying about building and managing things that don't differentiate you. This is a very big deal and this is what I believe serverless is all about.
I'd be happy to hear your thoughts on this subject, so please feel free to add a comment, or hit me up on Twitter.