How To: Use SNS and SQS to Distribute and Throttle Events
SNS distributing events to SQS is a powerful AWS serverless microservice pattern. This post shows how to create subscriptions, add filters, and throttle events.
An extremely useful AWS serverless microservice pattern is to distribute an event to one or more SQS queues using SNS. This gives us the ability to use multiple SQS queues to "buffer" events so that we can throttle queue processing to alleviate pressure on downstream resources. For example, if we have an event that needs to write information to a relational database AND trigger another process that needs to call a third-party API, this pattern would be a great fit.
This is a variation of the Distributed Trigger Pattern, but in this example, the SNS topic AND the SQS queues are contained within a single microservice. It is certainly possible to subscribe other microservices to this SNS topic as well, but we'll stick with intra-service subscriptions for now. The diagram below represents a high-level view of how we might trigger an SNS topic (API Gateway → Lambda → SNS), with SNS then distributing the message to the SQS queues. Let's call it the Distributed Queue Pattern.
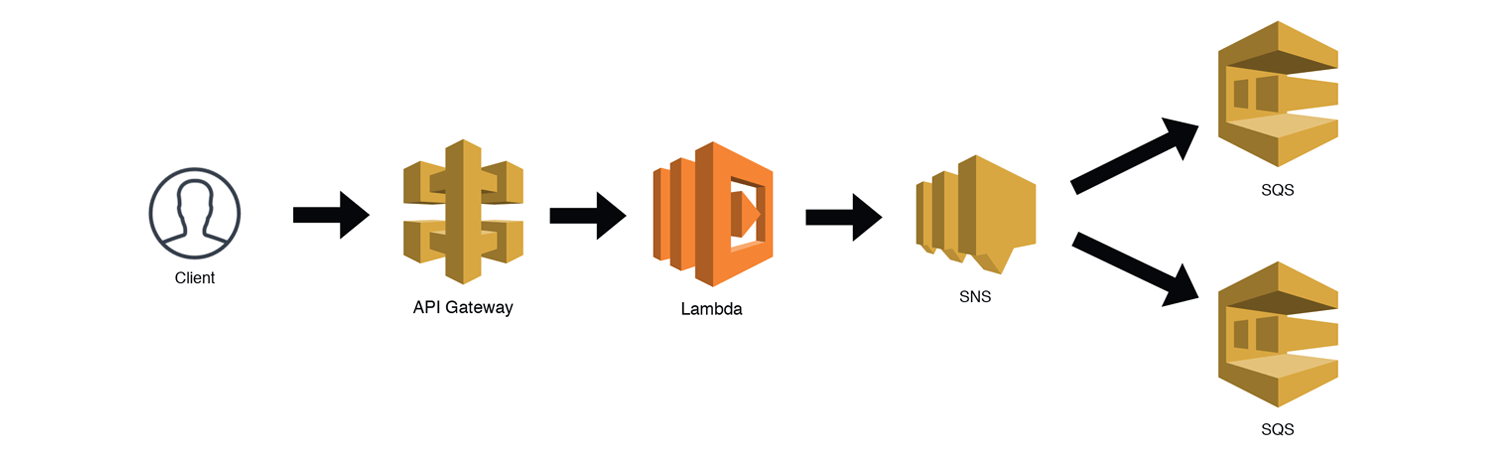
This post assumes you know the basics of setting up a serverless application, and will focus on just the SNS topic subscriptions, permissions, and implementation best practices. Let's get started!
SNS + SQS = 👍
The basic idea of an SQS queue subscribed to an SNS topic is quite simple. SNS is essentially just a pub-sub system that allows us to publish a single message that gets distributed to multiple subscribed endpoints. Subscription endpoints can be email, SMS, HTTP, mobile applications, Lambda functions, and, of course, SQS queues. When an SQS queue is subscribed to an SNS topic, any message sent to the SNS topic will be added to the queue (unless it's filtered, but we'll get to that later 😉). This includes both the raw Message Body, and any other Message Attributes that you include in the SNS message.
It is almost guaranteed that your SNS messages will eventually be delivered to your subscribed SQS queues. From the SNS FAQ:
SQS: If an SQS queue is not available, SNS will retry 10 times immediately, then 100,000 times every 20 seconds for a total of 100,010 attempts over more than 23 days before the message is discarded from SNS.
It is highly unlikely that your SQS queues would be unavailable for 23 days, so this is why SQS queues are recommended for critical message processing tasks. Also from the SNS FAQ:
If it is critical that all published messages be successfully processed, developers should have notifications delivered to an SQS queue (in addition to notifications over other transports).
So not only do we get the benefit of near guaranteed delivery, but we also get the benefit of throttling our messages. If we attempted to deliver SNS messages directly to Lambda functions or HTTP endpoints, it is likely that we could overwhelm the downstream resources they interact with.
It's also possible that we could lose events if we don't set up Dead Letter Queues (DLQs) to capture failed invocations when the services go down. And even if we did capture these failed events, we'd need a way to replay them. SQS basically does this automatically for us. Plus we may be the reason WHY the service went down in the first place, so using an HTTP retry policy might exacerbate the problem.
So don't think about queues between services as added complexity, think of it as adding an additional layer of durability.
Creating Subscriptions
AWS has a tutorial that shows you how to set up an SQS to SNS subscription via the console, but we want to automate this as part of our serverless.yml or SAM templates. AWS also provides a sample CloudFormation template that you can use, but this one doesn't create the appropriate SQS permissions for you. You can also use this CloudFormation template, but it creates IAM users and groups, which is overkill for what we're trying to accomplish.
Let's look at a real world example so we can better understand the context.
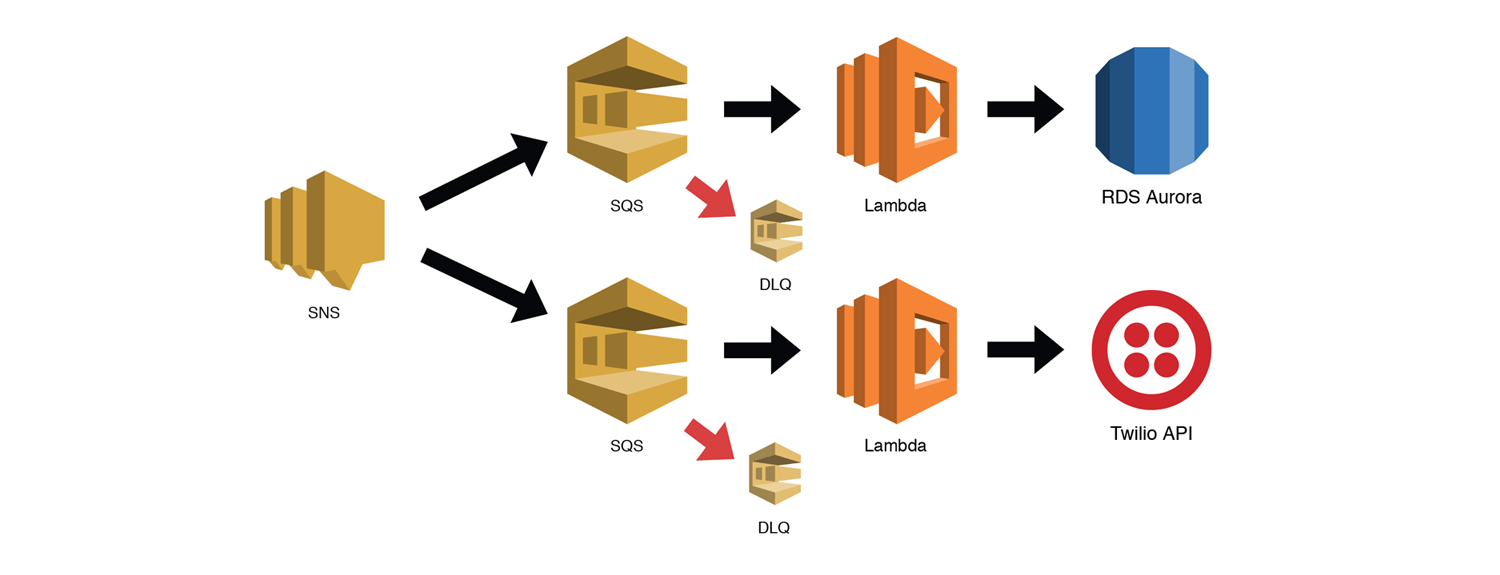
In the example above, our serverless application has two SQS queues subscribed to our SNS topic. Each queue has a Lambda function subscribed, which will automatically process messages as they are received. One Lambda function is responsible for writing some information to an RDS Aurora table, and the other is responsible for calling the Twilio API. Notice that we are using additional SQS queues as Dead Letter Queues (DLQs) for our main queues. We are using a redrive policy for our queues instead of attaching DLQs directly to our Lambda functions because SQS events are processed synchronously by Lambda. We would also be throttling our Lambdas by setting our Reserved Concurrency to an appropriate level for our downstream services.
Serverless Configuration
Now that we know what we're building, let's write some configuration files! 🤓 I'm going to use the Serverless Framework for the examples below, but they could easily be adapted for SAM.
Let's start with our resources. This is just straight CloudFormation (with a few Serverless Framework variables), but you could essentially just copy this into your SAM template. Take a look at this and we'll discuss some of the highlights below.
1# Resources section of your serverless.yml file23resources:4 Resources: 56 ### PART ONE: Create SNS Topic and SQS Queues78 # Create our SNS Topic9 mySnsTopic:10 Type: AWS::SNS::Topic11 Properties:12 TopicName: ${self:service}-${self:provider.stage}-my-sns-topic1314 # Create our 'firstQueue' SQS queue15 firstQueue:16 Type: "AWS::SQS::Queue"17 Properties:18 QueueName: ${self:service}-${self:provider.stage}-first-queue19 RedrivePolicy:20 deadLetterTargetArn: !GetAtt21 - firstQueueDLQ22 - Arn23 maxReceiveCount: 32425 # Create our 'firstQueue' Dead Letter Queue SQS queue26 firstQueueDLQ:27 Type: AWS::SQS::Queue28 Properties:29 QueueName: ${self:service}-${self:provider.stage}-first-queue-dlq3031 # Create our 'secondQueue' SQS queue32 secondQueue:33 Type: "AWS::SQS::Queue"34 Properties:35 QueueName: ${self:service}-${self:provider.stage}-second-queue36 RedrivePolicy:37 deadLetterTargetArn: !GetAtt38 - secondQueueDLQ39 - Arn40 maxReceiveCount: 34142 # Create our 'secondQueue' Dead Letter Queue SQS queue43 secondQueueDLQ:44 Type: AWS::SQS::Queue45 Properties:46 QueueName: ${self:service}-${self:provider.stage}-second-queue-dlq 4748 ### PART TWO: Create SQS Queue Policies4950 # Create our queue policy for the 'firstQueue'51 snsToFirstQueueSqsPolicy:52 Type: AWS::SQS::QueuePolicy53 Properties:54 PolicyDocument:55 Version: "2012-10-17"56 Statement:57 - Sid: "allow-sns-messages"58 Effect: Allow59 Principal: "*"60 Resource: !GetAtt61 - firstQueue62 - Arn63 Action: "SQS:SendMessage"64 Condition:65 ArnEquals:66 "aws:SourceArn": !Ref mySnsTopic67 Queues:68 - Ref: firstQueue6970 # Create our queue policy for the 'secondQueue'71 snsToSecondQueueSqsPolicy:72 Type: AWS::SQS::QueuePolicy73 Properties:74 PolicyDocument:75 Version: "2012-10-17"76 Statement:77 - Sid: "allow-sns-messages"78 Effect: Allow79 Principal: "*"80 Resource: !GetAtt81 - secondQueue82 - Arn83 Action: "SQS:SendMessage"84 Condition:85 ArnEquals:86 "aws:SourceArn": !Ref mySnsTopic87 Queues:88 - Ref: secondQueue8990 ### PART THREE: Subscribe our SQS Queues to our SNS Topic 9192 # Create the subscription to the 'firstQueue'93 firstQueueSubscription:94 Type: 'AWS::SNS::Subscription'95 Properties:96 TopicArn: !Ref mySnsTopic97 Endpoint: !GetAtt98 - firstQueue99 - Arn100 Protocol: sqs101 RawMessageDelivery: 'true'102103 # Create the subscription to the 'secondQueue'104 secondQueueSubscription:105 Type: 'AWS::SNS::Subscription'106 Properties:107 TopicArn: !Ref mySnsTopic108 Endpoint: !GetAtt109 - secondQueue110 - Arn111 Protocol: sqs112 RawMessageDelivery: 'true'
Part One is quite simple. We create our AWS::SNS::Topic, our two AWS::SNS::Queues, and create a RedrivePolicy in each that sends failed messages to our deadLetterTargetArns.
Part Two creates an AWS::SQS::QueuePolicy for each of our queues. This is necessary to allow our SNS topic to send messages to them. For you security sticklers out there, you may have noticed that we are using a * for our Principal setting. 😲 Don't worry, we are using a Condition that makes sure the "aws:SourceArn" equals our SnsTopic, so we're good.
Part Three does the actual subscriptions to the SNS topic. Be sure to set your RawMessageDelivery to 'true' (note the single quotes) so that no JSON formatting is added to our messages.
That takes care of our topic, queues and subscriptions, now let's configure our two functions. I've only included the pertinent configuration settings below.
1functions:23 rds-function:4 handler: rds-function.handler5 description: Writes to the database6 vpc: ... # our VPC info so we can connect to RDS7 reservedConcurrency: 58 events:9 - sqs:10 arn: !GetAtt11 - firstQueue12 - Arn13 batchSize: 11415 twilio-function:16 handler: twilio-function.handler17 description: Calls the Twilio API18 reservedConcurrency: 519 events:20 - sqs:21 arn: !GetAtt22 - secondQueue23 - Arn24 batchSize: 1
This is quite straightforward. We are are creating two functions, each subscribed to their respective SQS queues. Notice we are using the !GettAtt CloudFormation intrinsic function to retrieve the Arn of our queues. Also, notice that we are setting the reservedConcurrency setting to throttle our functions. We can adjust this setting based on the capacity of our downstream resource. SQS and Lambda's concurrency setting work together, so messages in the queue will remain in the queue until there are Lambda instances available to process them. If our Lambda fails to process the messages, they'll go into our DLQs.
Message Filtering for the Win! 👊
You may be asking yourself, why don't I just use Kinesis for this? That's a great question. Kinesis is awesome for handling large message streams and maintaining message order. It is highly durable and we can even control our throttling by selecting the number of shards. Yan Cui also points out that SNS can actually be considerably more expensive than Kinesis when you get to high levels of sustained message throughput. This is certainly true for some applications, but for spiky workloads, it would be less of a problem.
However, there's one thing that SNS can do that Kinesis can't: Message Filtering. If you are subscribed to a Kinesis stream, but you're only interested in certain messages, you still need to inspect ALL the messages in the stream. A common pattern is to use a single Kinesis stream as your "event stream" and subscribe several functions to it. Each function must load every message and then determine if it needs to do something with it. Depending on the complexity of your application, this may create a lot of wasted Lambda invocations.
SNS, on the other hand, allows us to add some intelligence to our "dumb pipes" by applying a FilterPolicy to our subscriptions. Now we can send just the events we care about to our SQS queues. This way we can minimize our Lambda invocations and precisely control our throttling. With Kinesis, every subscribed function is subject to the concurrency set by the shard count.
Setting up our filters is as simple as adding a FilterPolicy to our AWS::SNS::Subscriptions in our CloudFormation resources. If we only want messages that have an action of "sendSMS", our updated resource would look like this:
1# Create the subscription to the 'secondQueue'2secondQueueSubscription:3 Type: 'AWS::SNS::Subscription'4 Properties:5 TopicArn: !Ref mySnsTopic6 Endpoint: !GetAtt7 - secondQueue8 - Arn9 Protocol: sqs10 FilterPolicy:11 action:12 - 'sendSMS'13 RawMessageDelivery: 'true'
There are several types of filtering available, including prefix matching, ranges, blacklisting, and more. You can view all the different options and the associated syntax in the official AWS docs. The important thing to remember is that filters work on Message Attributes, so you will need to make sure that messages sent to your SNS topic contain the necessary information. And that's it. Now our secondQueue will only receive messages that have an action of "sendSMS", which means our Lambda function will only be invoked to process "sendSMS" actions.
Final Thoughts 🤔
This is an incredibly powerful pattern, especially if you need to throttle downstream services. However, like with anything, applying this pattern to your application depends on your requirements. This pattern does not guarantee the order of messages, so it's possible that new messages could be processed before older ones. Also, if you have very high message rates, SNS can get a bit expensive. Be sure to evaluate other Serverless Microservice Patterns for AWS to determine which patterns make the most sense for your use case.
If you're interested in learning more about serverless microservices, check out my Introduction to Serverless Microservices and Mixing VPC and Non-VPC Lambda Functions for Higher Performing Microservices posts.