Mixing VPC and Non-VPC Lambda Functions for Higher Performing Microservices
Learn how to mix and match your VPC and non-VPC based Lambda functions to create efficient serverless microservices in the AWS Cloud.
I came across a post the in the Serverless forums that asked how to disable the VPC for a single function within a Serverless project. This got me thinking about how other people structure their serverless microservices, so I wanted to throw out some ideas. I often mix my Lambda functions between VPC and non-VPC depending on their use and data requirements. In this post, I'll outline some ways you can structure your Lambda microservices to isolate services, make execution faster, and maybe even save you some money. ⚡️💰
Lambdas in your VPC
Lambda functions in VPCs are amazing. When they were introduced in early 2016, it opened up a whole new set of use cases for serverless compute layers. With VPC-based Lambda functions, you can access services like RDS, Elasticache, RedShift clusters, and now, private API Gateways. But all these benefits comes with a cost. Let's look at the three major issues with running Lambdas in VPCs.
1. ENI attachment time adds to cold starts
In order for your Lambda functions to securely connect to resources within your VPC, they need to create Elastic Network Interfaces (or ENIs). Since Lambda scales by invoking a function for each concurrent connection, a new ENI needs to be set up on almost every cold start. According to the documentation:
When a Lambda function is configured to run within a VPC, it incurs an additional ENI start-up penalty. This means address resolution may be delayed when trying to connect to network resources.
This means that your cold start times could increase dramatically. I've see a difference in upwards of 10 additional seconds to cold start a VPC versus non-VPC Lambda function.
2. Limited number of ENIs per VPC
Let's try to keep this simple. Your VPC is configured with a number of subnets. Each subnet has a range of IPs that are available to it. Every time a new concurrent Lambda function is invoked, a new ENI needs to be created and/or allocated. The documentation gives the following formula to estimate the number of ENIs required based on projected peak concurrent executions:
Projected peak concurrent executions * (Memory in GB / 3GB)
Using the above formula, here are some sample ENI estimations. The memory in GB is the amount of memory allocated to your function:
250 * (1,024 MB [1 GB] / 3 GB) = 84 ENIs
500 * (2048 MB [2 GB] / 3 GB) = 334 ENIs
50 * (3,008 MB [2.9375 GB] / 3GB) = 147 ENIs
1,000 * (3,008 MB [2.9375 GB] / 3GB) = 2,938 ENIs
The amount of ENIs can vary greatly depending on your use case, but the important thing to remember is:
AWS Lambda currently does not log errors to CloudWatch Logs that are caused by insufficient ENIs or IP addresses. (AWS docs)
If you do run out of ENIs, your Invocation Errors metric will increase, but it won't log it to CloudWatch. So make sure that you configure your VPC subnets to have enough IP addresses based on your projected peak concurrent executions.
💡 FUN FACT:
The amount of IP addresses available to your VPC subnets is based on the CIDR block you assign to it. These look like 10.0.0.0/24, which means there are 24 significant bits (out of a total of 32) used to calculate your IP range. If you have no idea what that means, you're not alone. The lower the number of significant bits (or your netmask), the more IP addresses available. For instance, 10.0.0.0/24 has 256 addresses (10.0.0.0 to 10.0.0.255), whereas 10.0.0.0/28 only has 16 (10.0.0.0 to 10.0.0.15).
You typically assign 2 or more private subnets to your VPC Lambda functions, so if each subnet has a CIDR block with 256 addresses, you might top out at just over 500. Remember that all functions in the VPC (as well as other VPC resources) share these addresses, so think about TOTAL CONCURRENCY, not just that of a single function. I typically use /22 netmasks with CIDR blocks, which gives me 1,024 addresses per subnet.
3. NAT Gateways are required for Internet access
When you add VPC configuration to a Lambda function, it can only access resources in that VPC. If a Lambda function needs to access both VPC resources and the public Internet, the VPC needs to have a Network Address Translation (NAT) instance inside the VPC. (AWS docs)
VPC subnet IP addresses are private, so they can't be used on a public network. If your function needs to access the Internet (e.g. call an external API), then you need to create a managed NAT Gateway. You not only pay by the hour for this service, but you also pay for data transferred through it.
Although you used to need a NAT Gateway to connect to AWS services like DynamoDB or Kinesis from a Lambda function inside your VPC, you can now set up a VPC endpoint. There is no charge for a Gateway VPC endpoint, so use this if you only need to connect to S3 or DynamoDB, there is no need to set up a NAT Gateway.
Lambdas NOT in your VPC
While VPC-based Lambdas provide us with a lot of great features, Lambdas that are NOT in your VPC are still incredibly powerful. Even though they are not in your VPC, they are still technically in a VPC. This means that these Lambdas are still plenty secure and can be used to pass around application information safely. It also turns out that the three problems with VPC-based Lambdas we mentioned above, are actually the major benefits of Lambdas NOT in a VPC.
Cold start times are ridiculously fast
The ENI start-up penalty is completely eliminated with non-VPC Lambdas. Even cold starts through API Gateway (depending on the memory allocation of your function) will often load in just a few hundred milliseconds. A lot better than the 10+ seconds it could take to cold start VPC functions.
Near infinite scaling
There are a number of limits imposed on Lambda functions (function size, execution time, etc.). But scaling is only restricted by an arbitrary concurrency limit, which can be raised if your use case supports it. Unlike VPC Lambdas, there is no need to allocate IP addresses for ENIs, so there are no additional limits.
Internet access out of the box
Non-VPC Lambdas use a default NAT that we don't have to worry about (or pay for), so we are free to access public resources on the Internet. This also includes AWS services like SNS, DynamoDB and Kinesis.
Serverless Microservices
I'm not going to go too deep into microservices in this post, but I do want to make sure we're all discussing the same thing. Microservices are loosely coupled services that are typically lightweight, highly modular, and self-contained. Building microservices with AWS Lambda is fairly straightforward and consists of creating a collection of one or more functions to handle a specific piece of your overall application.
Microservices have a number of benefits:
Each service can be written using different programming languages
Lambda provides several runtimes, and since each function is independent, your individual services do not need to all be written in one language. In fact, there are plenty of times where certain languages are better at handling a specific task. It's also possible that different teams may use different tools. This is no longer an issue when switching to a microservices architecture.
Services can be deployed and managed individually
One of the biggest problems with monolith applications, is that the entire application has to be deployed every time you want to release updates. For small applications, this might not be a big deal. But the larger your application gets and the more teams working on it, the bigger the pain and bottleneck it becomes. With microservices, small parts of the application can be deployed and iterated on quickly, without the need to redeploy your entire stack.
Multiple teams can develop services independently and in parallel
This is one of my favorites. Microservices should be designed to be "loosely coupled" and should maintain their own set of data (more on this in a bit). Being able to independently develop services can dramatically speed up development and provide teams with autonomy to use the tools and services needed to build the most efficient and effective version of their service. No more top-down approach to frameworks and other dependencies.
Services can be designed to scale
A service that convert a profile picture to the correct size is going to be accessed significantly less than a service that records website clickstreams. With traditional monolith applications, we tend to overprovision resources so that the parts of the service that need to scale, will scale. When we break our components into separate services, we can provision each function (or group of functions) to scale accordingly. This might mean limiting the concurrency of functions that have service bottlenecks (like RDS or rate-limited APIs), or opening the floodgates so that it can handle thousands of concurrent connections.
Services can be replaced
Another great feature of microservices is the modularity of each individual service. If you have a function that transcodes videos, you might originally deploy that using a third party API. As time goes on, you may decide that you want to switch to using AWS's Elastic Transcoder service. With a traditional monolith, you'd develop out the new feature, launch it to staging, maybe even split test it so that you can be sure it works. Then when you're ready, you launch it to production. With microservices, we can develop a new service using the same communication format, and then test it independently of our production pipeline. When ready, we can even canary test the service to make sure we're bulletproof. One click (speaking figuratively, of course) and you can replace your existing service without any interruption to the production application.
Microservice Communication Patterns
Immediately you're thinking, but if the services aren't connected, how do they communicate with one another? Great question. There are a number of ways to have microservices "talk" to one another, but these boil down to two main types: synchronous and asynchronous.
Synchronous Communication
Services can be invoked by other services and must wait for a reply. This is considered a blocking request, because the invoking service cannot finish executing until a response is received.
Synchronous communication in serverless architectures might consist of calling an internal API or invoking another Lambda function with a RequestResponse invocation type.
Asynchronous Communication
This is a non-blocking request. A service can invoke (or trigger) another service directly or it can use another type of communication channel to queue information. The service typically only needs to wait for confirmation that the request was sent.
Asynchronous communication with Lambda might be sending a message to SQS or SNS, writing to a Kinesis stream, or invoking another Lambda function with an Event invocation type. Asynchronous communication can also be used to send data to multiple receivers, which can help to propagate data to multiple services.
Understanding Eventual Consistency
If you have a relational database background, the idea of "normalization" was probably drilled into your head. For those unfamiliar with this concept, database normalization is the process of restructuring your data model in order to reduce data redundancy. You would typically use JOINS in your queries to load enumerated values. So for example, you would have a table that stored Countries and each would have a unique identifier (generally an integer). Any table that referenced a country would store the ID of the country, not the country name itself. This works great with many monolith applications, but not so much when we start to talk about web scale.
Many years ago I built my first sharded database infrastructure. I had to unlearn normalization in order to understand how to replicate data across shards so that joins were possible, even if the corresponding entities needed to be accessed from entirely different systems. Referential integrity be damned! This concept if very similar to a pattern we often use with microservices called eventual consistency.
Duplicated data is not always a bad thing, especially if it will facilitate a system request by having it located as close to the service using it as possible. Let's say we have a Users table that stores detailed information about them (email, birthday, etc.). We also have a Posts table that needs to reference the User who authored it. In a traditional data approach, we might just store the user's ID in the Posts table and then join at runtime. If we separate both of these into separate microservices (in order to decouple the services as best practices suggest), then we would have to make a separate call to the User service in order to get information about a Post's author. Or do we?
If we denormalize our data, and store the parts of the user's information we need to know in our Posts service, then we no longer require a separate call. We may only need the author's id, username and profile picture. When a new post is created, we simply call the Users service to get the information and save it along with our Post data. Then when we display a list of posts, the username and profile picture are there. Maybe our UI has a hover action when you mouse over the profile picture. That could be accomplished with an API call to the Users service if full details are required.
But wait, what if the user updates their username in the Users service? Another good question. This is where the concept of eventual consistency comes in. If the user updates their username, the User service could ping the Posts service and tell it to update the information. It could publish a message to SQS and the Posts service could consume that message and make the update. The Posts service could periodically poll the User service and get a list of changes since its last convergence. How the data is replicated doesn't really matter. The underlying concept is that services have a responsibility to notify other services of data changes.
This is where we tend to lose people. Most people think that any one of the solutions above sounds like it is prone to failure. And they'd be right. Eventual consistency is a weak guarantee, and without properly reconciling the data, you may end up with information that is out of sync. However, this just needs to be considered as part of your microservices design. If the data is critical, then maybe the two services should be coupled more closely. If taking some extra time to let data propagate isn't a problem, separate services might make more sense.
Multicast with SNS (for the win!)
The solutions to consistency I mentioned above are all perfectly valid ways to achieve eventual consistency. However, I often have multiple services that need to know if something has changed. I don't want to depend on the service that is the single source of truth for a set of data to notify dependent services. This would require an update to that service everytime a new dependent was added. Instead, we can create an SNS topic that gets notified whenever data changes. Then we can subscribe our dependent services. This, in effect, multicasts the changes and requires no update to our original service when new ones are added. If the change sets are likely to be large, I'll often have the subscribed service poll the original service for updates.
Putting it all together
Whew, it took us a while to get here, but now you should have a basic understanding of serverless microservices and the pros and cons of using VPC versus non-VPC Lambdas. So let's look at a rudimentary application that combines what we just learned. Look at the network diagram below. It is far from complete, but let me walk you through it to see how we might mix VPC and non-VPC Lambdas in a microservices design.
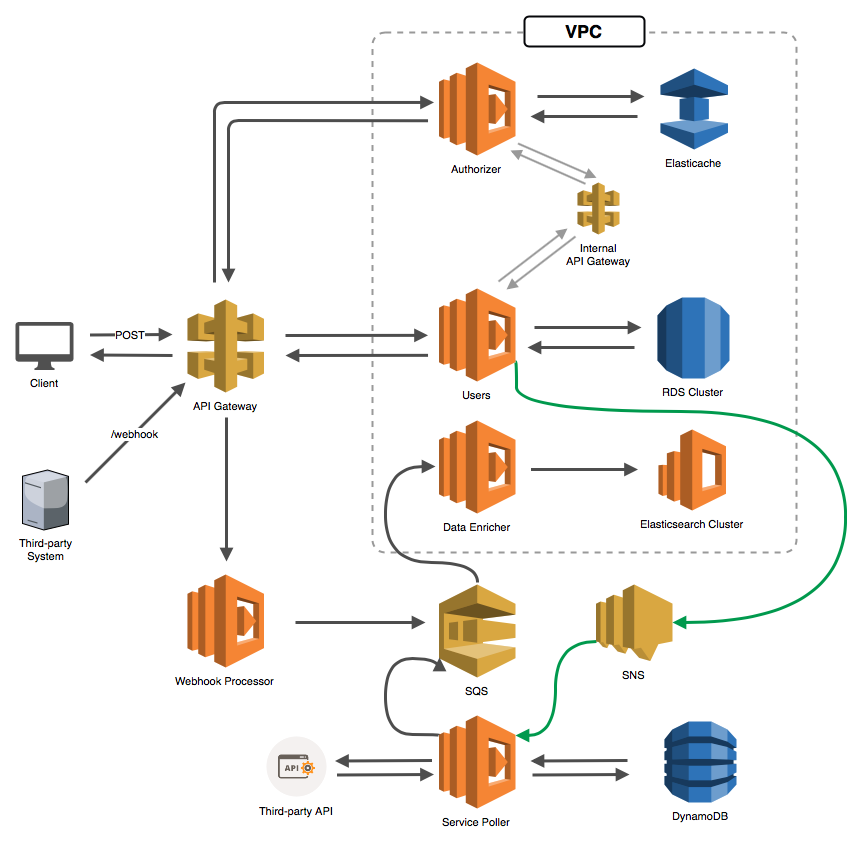
- Our client posts data to the API Gateway (presumably a
/usersendpoint) - The API Gateway calls our API Gateway Authorizer Lambda function
- The Authorizer function attempts to look up the authorization headers in Elasticache
- If it doesn't find them, it makes a synchronous call to an internal API Gateway (perhaps a
/lookupAuthendpoint) - This forwards the request to our Users function (which is the main interface into our Users service)
- The function looks up the user authentication in our RDS cluster
- The data is returned from the Users service to the Authorizer
- The Authorizer caches the data, then returns a policy to our API Gateway
- The authorized request is then forwarded to our Users function, which presumably updates the RDS cluster with the posted information
- Upon confirmation that the data was updated, the Users function posts a message to an SNS topic
- The Service Poller (a separate microservice) is subscribed to that SNS topic, so it gets notified
- The Service Poller accepts the SNS message and updates its DynamoDB table with the pertinent information it needs
- The Service Poller continues to poll a third-party API for some information that we want to retrieve regularly
- When new information is retrieved, the Service Poller pushes the data into an SQS queue
- Sometimes, third-party systems post data to our webhook, which is just another route on our public API
- The API routes the data to our Webhook Processor service
- The Webhook Processor pushes the data into our SQS queue (maybe even using the same standard format that the Service Poller uses)
- The Data Enrichment service monitors the SQS queue, and triggers our Data Enricher function whenever there are new messages
- The Data Enricher function does some magic (normalizes phone numbers, cleans up text, etc.)
- The function then pushes data into our Elasticsearch cluster
There are obviously a few additional complexities, but hopefully this illustrates a number of important points:
- We can easily separate our areas of concern into microservices
- We can use the benefits of non-VPC Lambdas (like out of the box Internet access and fast start times) to process massive amounts of webhook traffic and third-party API calls (all without using our ENIs)
- We can sync data between services using internal API Gateways, SNS topics, SQS queues and more
- We can isolate our primary data repositories in a VPC and access them with our VPC-based Lambdas
Mixing functions with Serverless
If you're using the Serverless framework (and you probably should be), you can easily mix and match functions in your VPC using the vpc field at the function level. I create a custom vpc variable and reference that in my VPC functions:
1# Add custom vpc variable2custom:3 vpc:4 securityGroupIds:5 - sg-XXXXXXXX6 subnetIds:7 - subnet-XXXXXXXX8 - subnet-XXXXXXXX9 - subnet-XXXXXXXX1011# Add vpc config to specific functions12functions:13 myFuncInVPC:14 handler: handler.myHandler15 vpc: ${self:custom.vpc}16 myFuncNotInVPC:17 handler: otherhandler.myHandler
Where do we go from here?
We've only scratched the surface of serverless microservices in this post. There are a lot of good articles around the web about microservices architecture and how to separate your services and data. I suggest you spend some time reading up on the different patterns used to facilitate communication between services and how to handle and retry communication failures. There is a lot to absorb here, but a well-designed serverless infrastructure will not only perform above and beyond your expectations, but it will let you sleep at night as well.
Good luck, and happy serverlessing (not a word)!⚡️😀😉