Serverless Consumers with Lambda and SQS Triggers
AWS Lambda now supports SQS triggers to invoke serverless functions. See how this new feature can turn the Simple Queue Service into a true message broker.
On Wednesday, June 27, 2018, Amazon Web Services released SQS triggers for Lambda functions. Those of you who have been building serverless applications with AWS Lambda probably know how big of a deal this is. Until now, the AWS Simple Queue Service (SQS) was generally a pain to deal with for serverless applications. Communicating with SQS is simple and straightforward, but there was no way to automatically consume messages without implementing a series of hacks. In general, these hacks "worked" and were fairly manageable. However, as your services became more complex, dealing with concurrency and managing fan out made your applications brittle and error prone. SQS triggers solve all of these problems. 👊
Update September 3, 2020: There are a number of important recommendations available in the AWS Developer Guide for using SQS as a Lambda Trigger: https://docs.aws.amazon.com/lambda/latest/dg/with-sqs.html.
The most important are:
"To allow your function time to process each batch of records, set the source queue's visibility timeout to at least 6 times the timeout that you configure on your function. The extra time allows for Lambda to retry if your function execution is throttled while your function is processing a previous batch."
"To give messages a better chance to be processed before sending them to the dead-letter queue, set the maxReceiveCount on the source queue's redrive policy to at least 5."
It is also imperative that you set a minimum concurrency of 5 on your processing Lambda function due to the initial scaling behavior of the SQS Poller.
Update November 19, 2019: AWS announced support for SQS FIFO queues as a Lambda event source (announcement here). FIFO queues guarantee message order, which means only one Lambda function is invoked per MessageGroupId.
Update December 6, 2018: At some point over the last few months AWS fixed the issue with the concurrency limits and the redrive policy. See Additional experiments with concurrency and redrive polices below.
Attaching Consumers to Message Brokers
It's a common architecture design pattern to attach consumers to message brokers in distributed applications. This becomes even more important with microservices as it allows communication between different components. Depending on the type of work to be done (high versus low priority), message brokers can be passive, simply storing messages and waiting for a message-oriented middleware to poll it, or active, where it will route the message for you.
RabbitMQ, for example, allows you to create bindings that attach workers to queues. You can run workers in the background with something like supervisor, which will get messages pushed to them as RabbitMQ receives them. Until now, SQS has lacked the ability to do this type of "push" and instead required constant polling to achieve a similar effect. This constant polling might make sense for high volume queues, but for smaller, occasional jobs, even running a Lambda function every minute would be a waste of resources.
Setting up an SQS trigger in Lambda is simple through the AWS Console. SAM templates also support this (https://github.com/becloudway/aws-lambda-sqs-sam) so you can set it up using that as well. The team at Serverless has implemented this is working to add this in too. The only required settings are the queue you want to access and the "batch size", which is the maximum number of messages that will be read from your queue at once (up to 10 at a time). Be sure to configure your IAM permissions properly, you need read and write privileges.
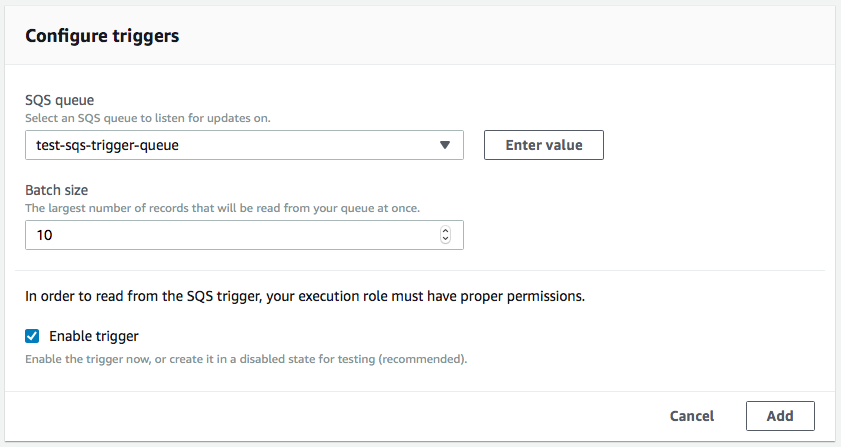
Running Some Experiments
I set up two test functions to run some experiments. The first was the function that was triggered by SQS and received the messages:
1let counter = 1;2let messageCount = 0;3let funcId = "id" + parseInt(Math.random() * 1000);45exports.handler = async (event) => {6 // Record number of messages received7 if (event.Records) {8 messageCount += event.Records.length;9 }10 console.log(funcId + " REUSE: ", counter++);11 console.log("Message Count: ", messageCount);12 console.log(JSON.stringify(event));13 return "done";14};
The second was a "queue flooder" that just generated random messages and sent them to the queue. Remember that SQS can only handle batches of 10:
1const AWS = require("aws-sdk");2const SQS = new AWS.SQS();3const queue =4 "https://sqs.us-east-1.amazonaws.com/XXXXXXXXXX/test-sqs-trigger-queue";56exports.handler = async (event) => {7 // Flood SQS Queue8 for (let i = 0; i < 50; i++) {9 await SQS.sendMessageBatch({10 Entries: flooder(),11 QueueUrl: queue,12 }).promise();13 }14 return "done";15};1617const flooder = () => {18 let entries = [];1920 for (let i = 0; i < 10; i++) {21 entries.push({22 Id: "id" + parseInt(Math.random() * 1000000),23 MessageBody: "value" + Math.random(),24 });25 }26 return entries;27};
I then ran my queue flooder. It sent 500 messages to SQS, which triggered my receiver function and drained the queue! 🙌
The event looks like this:
1{2 "Records": [3 {4 "messageId": "9cf06c9b-e919-4ef9-8485-3d13c347a4d1",5 "receiptHandle": "AQEBJRZxkQUWQYAwBMPpN4...rVCoU70HTdEVH4eKZXuPUVBw==",6 "body": "value0.6888803697786434",7 "attributes": {8 "ApproximateReceiveCount": "1",9 "SentTimestamp": "1530189332727",10 "SenderId": "AROAI62MWIO3S4UBJVPVG:sqs-flooder",11 "ApproximateFirstReceiveTimestamp": "1530189332728"12 },13 "messageAttributes": {},14 "md5OfBody": "7ce3453347fd9bd30281384c304a1f9d",15 "eventSource": "aws:sqs",16 "eventSourceARN": "arn:aws:sqs:us-east-1:XXXXXXXX:test-sqs-trigger-queue",17 "awsRegion": "us-east-1"18 }19 ]20}
The SQS trigger spawned 5 concurrent Lambda functions that took less than 2 seconds to process all of the messages. Pretty sweet! This got me thinking about how Lambda would handle thousands of messages as once. Would it spawn hundreds of concurrent functions? 🤔
Concurrency Control for Managing Throughput
My first thought was that Lambda's default scaling behavior would continue to fan out to process messages in the queue. This behavior makes sense if you're doing something like processing images and there are no bottlenecks to contend with. However, what if you're writing to a database, calling an external API, or throttling requests to some other backend service? Unlimited scaling is sure to cause issues if hundreds or thousands of Lambda functions are competing for the same resource. Luckily for us, we have concurrency control! 🤘🏻
I ran a few experiments to see exactly how Lambda would handle throttling requests. I used my queue flooder again and set the concurrency to 1. I sent 100 messages to the queue. Here are the log results:

It ultimately used two functions to handle the workload, but they executed serially, never exceeding my concurrency limit. As you can see, 100 messages were eventually processed over the course of 40 total invocations. Brilliant! 😀
I ran a second experiment to scale up my workload. I set the concurrency to 2 and flooded the queue with 200 messages this time.

Four functions in total were used, with only two running concurrently. And all 200 messages were processed successfully! 😎
Additional experiments with concurrency and redrive polices
Update December 6, 2018: The "Lambda service" now takes concurrency into account and no longer considers throttled invocations to be failed delivery attempts. This means that you can set a redrive policy on your queue and the system will only forward messages to a DLQ if there is an error while processing the message! 🙌
I've left the original information below to preserve the history, but most of this section is no longer relevant.
I had a really great comment that pointed out how adding redrive policies to SQS queues causes issues when you set a low concurrency. I ran some additional tests and discovered some really interesting behaviors.
It appears that the "Lambda service" polls the queue, and puts messages "in flight" without consideration of the concurrency limits. I added a 100ms wait time to my receiver function and noticed that messages towards the end of processing have ApproximateReceiveCounts of 4 or more. I'm sure this would be exacerbated by longer execution times and higher message volumes. The good news is that each message was only processed by my function one time.
I then set a redrive policy of But now this got me thinking about error handling. So I added some code to trigger an error in my receiver (1, and ran my "queue flooder" again. This time a large percentage ended up in the Dead Letter Queue. This makes sense given how the Lambda Service polls for messages.throw new Error('some error')) for every 10 requests, this turned out to be a really bad idea! I set my redrive policy to 1,000 Maximum Receives and then I sent 100 messages into the queue. 90 of the messages got processed (as expected), but the other 10 just kept on firing my Lambda function. Over and over again. 😳 I assume that it would have eventually stopped after those 10 messages had been tried 1,000 times each.
I think the concurrency control needs a bit of work. However, I believe that Lambda triggers are still usable if you manage the redrive policy yourself. If returning errors from the Lambda function doesn't tell the Lambda service to DLQ the message, then perhaps this just needs to be handled by our receiver functions. I don't think I really care how many times a message needs to be retried as long as it is eventually processed. If there is an issue with the message (e.g. it throws some error and needs to be inspected later), then I can handle that in a number of ways, including pushing it to a DLQ myself or logging it somewhere else.
It probably comes down to your particular use case, but throttling still seems possible, so long as you don't rely on SQS's built in redrive functionality.
This is a Game Changer 🚀
As you probably can tell, I'm a bit excited about this. Being able to use the Simple Queue Service as a true message broker that you can attach consumers to changes the way we'll build serverless applications. One of the biggest challenges has been throttling backend resources to avoid hitting service limits. With SQS triggers and concurrency control we can now offload expensive (or service limited) jobs without the need to hack something with scheduled tasks or CloudWatch log triggers. There's no longer a need to manage our own fan out operations to process queues. We can now simply choose how many "workers" we want processing our queued requests.
Think of the possibilities! We can trigger SQS from Dead Letter Queues to create our own redrive processes. We could queue data mutations, knowing that they will be processed almost instantaneously by our workers (reducing latency and costs of API responses). We can batch process and throttle remote API calls. My brain is spinning. 🤯
The team at AWS has once again pushed the envelope for serverless computing. Congrats! Know that your work is appreciated. You're awesome. 🙇♂️
Update: Read the official announcement by AWS.
Interested in learning more about serverless? Check out 10 Things You Need To Know When Building Serverless Applications to jumpstart your serverless knowledge.
If you want to learn more about serverless security, read my posts Securing Serverless: A Newbie's Guide and Event Injection: A New Serverless Attack Vector.