Aurora Serverless: The Good, the Bad and the Scalable
Take a deep dive into the pros and cons of Amazon's new Aurora Serverless service and find out if it's right for you and your company's needs and budget.

Amazon announced the General Availability of Aurora Serverless on August 9, 2018. I have been playing around with the preview of Aurora Serverless for a few months, and I must say that overall, I'm very impressed. There are A LOT of limitations with this first release, but I believe that Amazon will do what Amazon does best, and keep iterating until this thing is rock solid.
The announcement gives a great overview and the official User Guide is chock full of interesting and useful information, so I definitely suggest giving those a read. In this post, I want to dive a little bit deeper and discuss the pros and cons of Aurora Serverless. I also want to dig into some of the technical details, pricing comparisons, and look more closely at the limitations.
Audio Version
Update May 2, 2019: Amazon Aurora Serverless Supports Capacity of 1 Unit and a New Scaling Option
Update November 21, 2018: AWS released the Aurora Serverless Data API BETA that lets you connect to Aurora Serverless using HTTP as opposed to a standard MySQL TCP connection. It isn't ready for primetime, but is a good first step. You can read my post about it here: Aurora Serverless Data API: A First Look.
What is Aurora Serverless?
Let's start with Aurora. Aurora is Amazon's "MySQL and PostgreSQL compatible relational database built for the cloud, that combines the performance and availability of high-end commercial databases with the simplicity and cost-effectiveness of open source databases." If you are using MySQL or PostgreSQL, you can basically migrate to Aurora without any changes to your application code. It's fully-managed, ridiculously fast (up to 5x faster than MySQL), and can scale using shared-storage read replicas and multi availability zone deployments. This extra power (and convenience) comes with an added cost (~23% more per hour), but I've found it to be well worth it.
Now let's talk about the "serverless" part. Yes, serverless has servers (I'm getting sick of typing this 🤦🏻♂️), but the general idea is that for something to be "serverless", it should:
- Charge you only for what you use
- Require zero server maintenance
- Provide continuous scaling
- Support built-in high availability and fault tolerance
Aurora Serverless provides an on demand, auto-scaling, high-availability relational database that only charges you when it's in use. While it may not be perfect, I do think that this fits the definition of serverless. All you need to do is configure a cluster, and then all the maintenance, patching, backups, replication, and scaling are handled automatically for you. It almost sounds too good to be true, so let's jump in and investigate.
Setting up your Aurora Serverless cluster
Setting up an Aurora Serverless cluster is fairly simple. Note that you can only create a cluster in a VPC.
1. Click "Create Database" from the main RDS Console screen or from within "Instances" or "Clusters"
2. Select "Amazon Aurora" and the "MySQL 5.6-compatible" edition (Aurora Serverless only supports this edition) and click "Next"
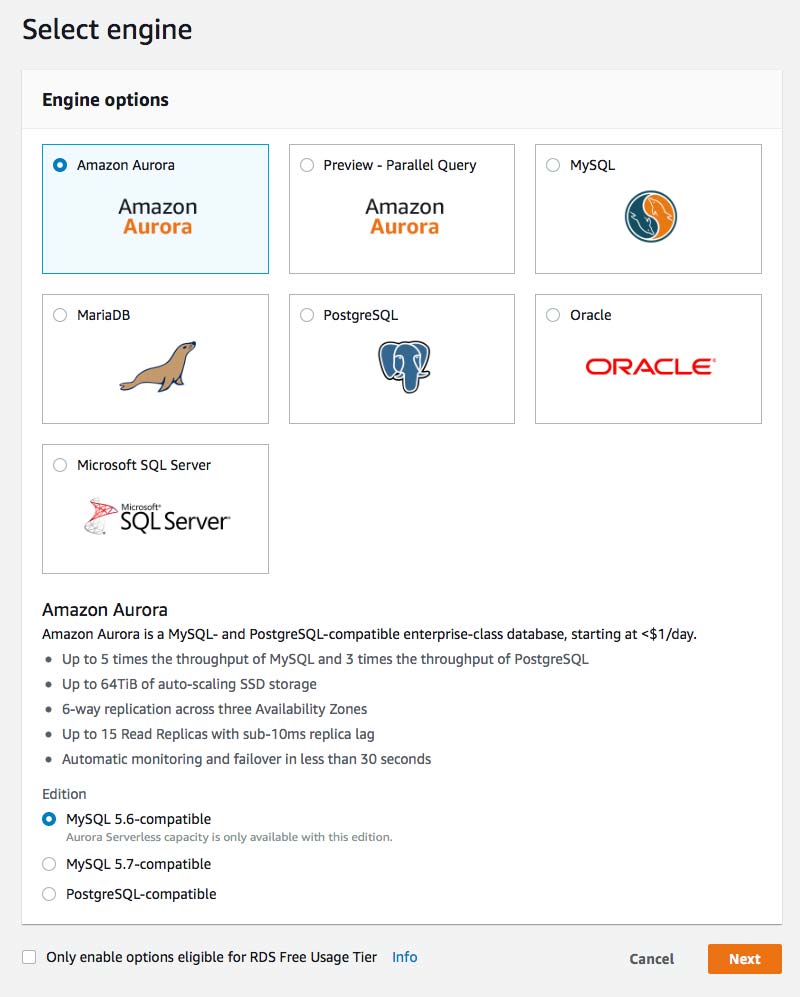
3. Select "Serverless" as the DB engine, enter the cluster settings including the identifier, master username and password, then click "Next"
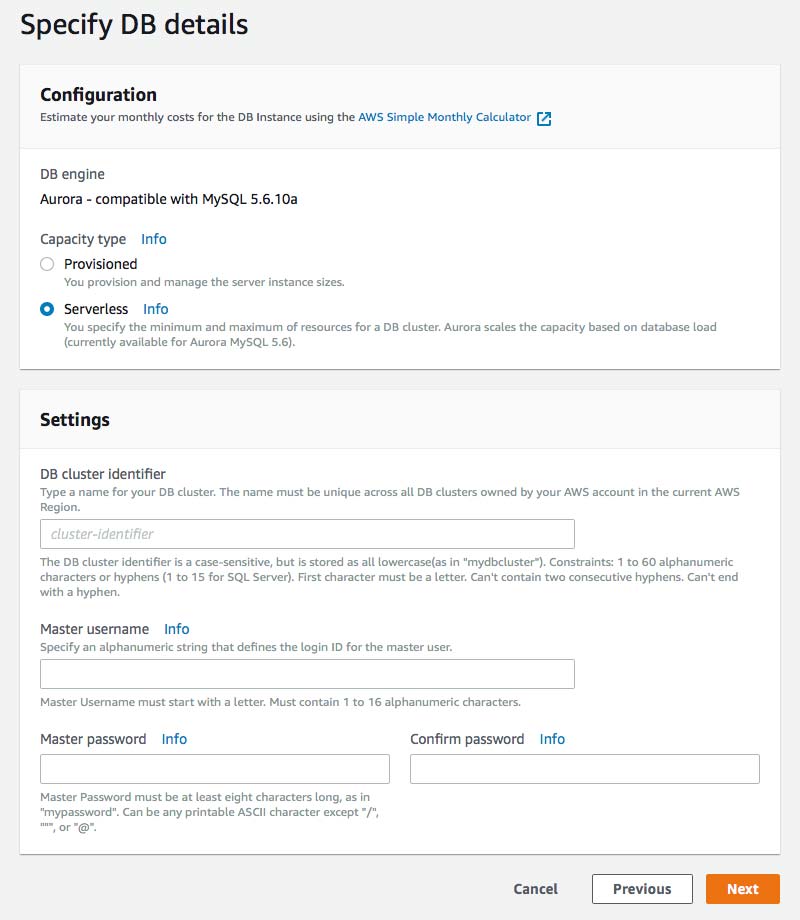
4. Select your "Capacity settings" and your "Additional scaling configuration" to control auto-pause settings
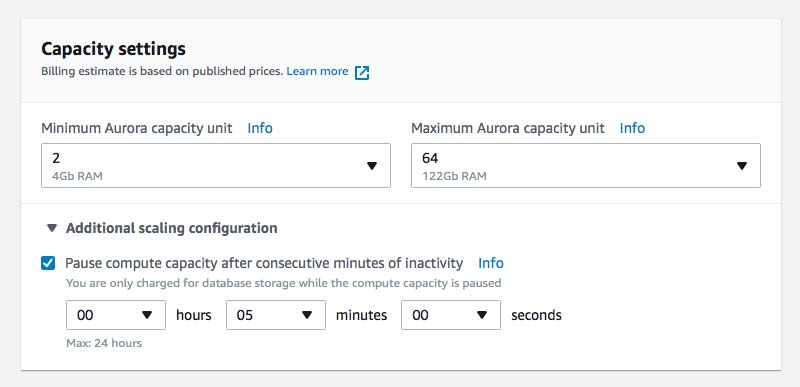
5. Configure "Network & Security" by selecting (or creating) a VPC and subnet group as well as choosing (or creating) VPC security groups
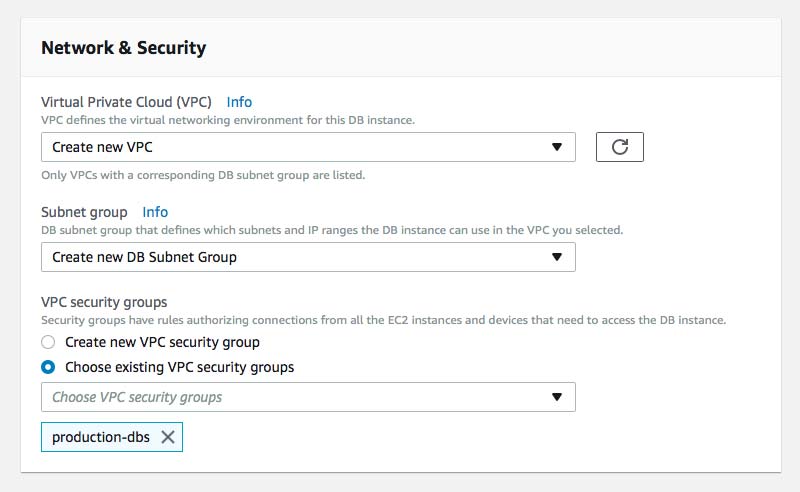
6. Expand "Additional configuration" and confirm your parameter group, backup retention setting and your encryption key and then click "Create database"
Note that data at rest in Serverless Aurora clusters appears to be automatically encrypted using KMS. There is no option to disable it.
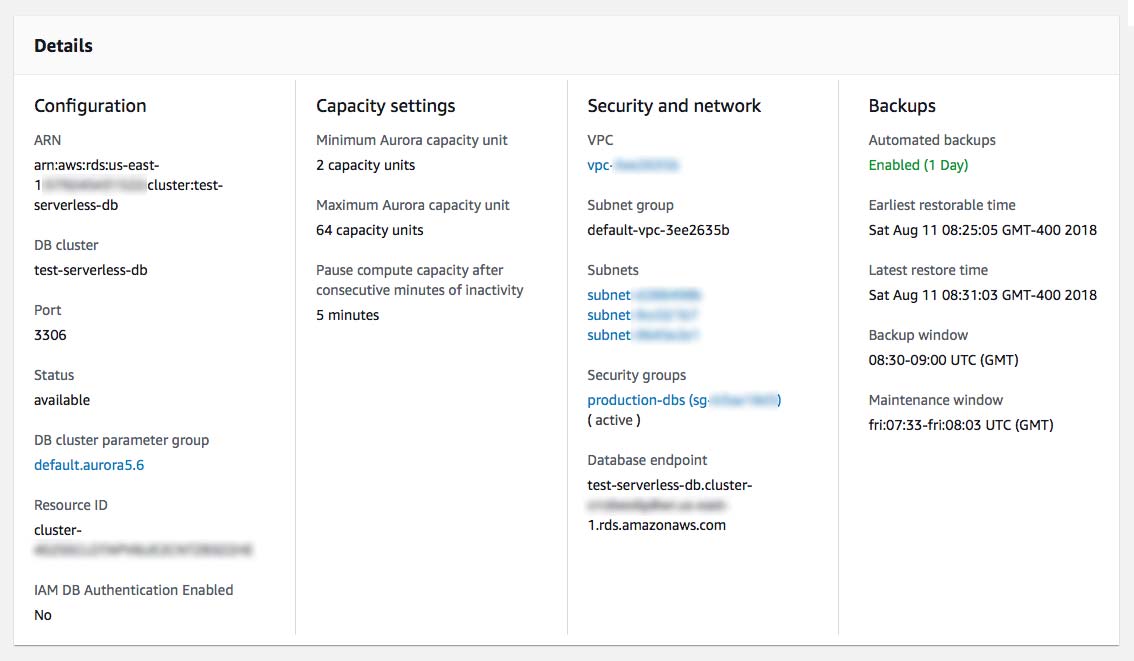
It took just over 2 minutes to create the cluster for me. Once it is available, you can view the cluster information by clicking on "Clusters" in the left menu and then clicking on your cluster name in the list.
This dashboard is quite robust, with lots of CloudWatch metrics (including the ability to compare clusters) and detailed information about your cluster configuration. From here you can also grab your "Database endpoint".
Connecting to your Aurora Serverless Cluster
From a connection standpoint, your Aurora Serverless cluster is very similar to a regular Aurora cluster. Any VPC resource that has access to your cluster (based on your chosen security groups) can connect to your cluster on port 3306. If you have an existing EC2 instance (with proper security group access and the mysql CLI tools installed), you can connect from your terminal using the standard:
mysql -u root -h test-serverless-db.cluster-XXXXXXXXXX.us-east-1.rds.amazonaws.com -p
If you want to connect to your cluster from your local machine, you can either connect through a VPN, or set up an SSH tunnel. You can configure an SSH tunnel by adding the following to your ~/.ssh/config file:
default# Serverless Tunnel Host tunnel HostNameUser ec2-user IdentitiesOnly yes IdentityFile ~/.ssh/ .pem LocalForward 3306 test-serverless-db.cluster-XXXXXX.us-east-1.rds.amazonaws.com:3306
Then simply run ssh tunnel -Nv in your terminal. From another terminal window run:
mysql -u root -h 127.0.0.1 -p
And that should connect you. I wrote a detailed post about how to do this with Elasticsearch in a VPC. That should give you more detailed information if you have an issue with the above setup.
Your applications would connect just like they would to any other MySQL database. I was able to easily add my new cluster to phpMyAdmin and connect from Lambda using the mysql node package.
Limitations of Aurora Serverless
As I mentioned earlier, there are A LOT of limitations to Aurora Serverless. However, depending on your use case, most of these probably won't matter much and will have little to no impact on your application.
A few top level limitations:
- Aurora Serverless is only compatible with MySQL 5.6
- The port number for connections must be 3306
- Aurora Serverless DB clusters can only be accessed from within a VPC
- AWS VPN connections and inter-region VPC peering connections are not able to connect to Aurora Serverless clusters
You are also extremely limited with your ability to modify cluster-level parameters in custom Cluster Parameter groups. As of now, you can only modify the following cluster-level parameters:
character_set_servercollation_serverlc_time_nameslower_case_table_namestime_zone
Modifying other cluster-level parameters would have no effect since Aurora Serverless uses the default values. Instance-level parameters are not supported either. Noticeably absent here is the max_connections parameter. See Max Connections below for more information.
There are also several other features that Aurora Serverless doesn't currently support. Some of these features are quite useful when using provisioned Aurora, so these might be a dealbreaker if you are relying on any of the following:
- Loading data from an Amazon S3 bucket This is a great feature for bulk loading data into your MySQL database, especially if you're using Aurora for reporting. Aurora Serverless doesn't have support yet.
- Invoking an AWS Lambda function with an Aurora MySQL native function This is one of Aurora's greatest features, essentially giving you the ability to create triggers based on actions in your MySQL database. Comparable to DynamoDB streams.
- Advanced auditing Useful for some applications, but something I can live without.
- Aurora Replicas This is another great feature of Aurora that scales reads by creating new instances that access the same shared cluster volume. I'm sure Amazon thought this through, but I wonder how auto-scaling of Aurora Serverless compares.
- Backtrack Another unique feature of Aurora is the ability to rewind and fast-forward transactions in your cluster. This isn't available in Aurora Serverless.
- Database cloning If you are using database cloning (especially for things like chaos engineering), you're out of luck with Aurora Serverless.
- IAM database authentication This is a nice and secure way to protect security credentials, but since Aurora Serverless doesn't have public endpoints, it probably isn't a huge deal.
- Cross-region read replicas Helpful for disaster recover, but I think it is unnecessary given the built-in high availability and distributed nature of Aurora Serverless.
- Restoring a snapshot from a MySQL DB instance Not a huge deal if you are already using Aurora. If you are migrating from MySQL, you could always migrate to an Aurora provisioned cluster and then to Serverless.
- Migrating backup files from Amazon S3 Same as above. Useful, but there are workarounds.
- Connecting to a DB cluster with Secure Socket Layer (SSL) Again, useful for security, but not necessary if using username/password to connect.
If none of these limitations affect you, then Aurora Serverless might be right for your use case. Let's look at the cost comparison between using provisioned versus serverless cluster.
Cost comparisons
Both provisioned and serverless versions of Aurora charge you for storage, I/O, and data transfer. Storage and I/O are flat rates per corresponding unit of measure:
| Storage Rate | $0.10 per GB-month |
| I/O Rate | $0.20 per 1 million requests |
Data transfer rates from Amazon RDS to the Internet shouldn't apply to Aurora Serverless since it can't be accessed directly from the Internet. However, depending on where data is being transferred to within AWS, data transfer fees may apply. Below is a small sample of the pricing for data transfer.
| Data Transfer OUT From Amazon RDS To | |
| CloudFront | $0.00 per GB |
| US East (N. Virginia) | $0.01 per GB |
| Asia Pacific (Mumbai) | $0.02 per GB |
| Asia Pacific (Sydney) | $0.02 per GB |
| EU (London) | $0.02 per GB |
| Complete pricing https://aws.amazon.com/rds/aurora/pricing/ | |
NOTE: Data transferred between Amazon RDS and Amazon EC2 Instances in the same Availability Zone is free.
The real difference in pricing is based on the way Aurora Serverless scales and how it charges for usage. Provisioned Aurora instances utilize per hour billing based on instance size, like EC2 and other virtual instances. Aurora Serverless, on the other hand, uses ACUs (or Aurora Capacity Units) to measure database capacity. Each ACU has approximately 2 GB of memory with corresponding CPU and networking resources that are similar to provisioned instances of Aurora.
ACUs are billed by the second at a flat rate of $0.06 per hour. Even though you are only billed per second of usage, there is a minimum of 5 minutes billed each time the database is active. There is also a minimum provisioning of 2 ACUs (with 4 GB of memory). Updated May 2, 2019: You can now set your minimum capacity to 1 ACU (with 2 GB of memory) if you are using the MySQL version. PostgreSQL still has a minimum of 2 ACUs. You can scale all the way up to 256 ACUs with approximately 488 GB of memory. If you were to keep an Aurora Serverless database running 24 hours per day at 2 ACUs, it would cost you $2.88 ($0.06 * 2 * 24) per day (or roughly $86 per month). If you scale down to 1 ACU (on MySQL), the base cost (without and scale ups) would be about $43 per month.
In order to compare apples to apples, I've created a chart below that makes some assumptions based on corresponding memory to see the difference in cost between provisioned versus serverless. The instance prices below reflect on-demand pricing, which are obviously much higher than reserved instances.
| ACUs | Memory (GB) | Serverless/hr | Instance Type | Cost/hr | Diff/hour | Diff/month |
|---|---|---|---|---|---|---|
| 1 | 2 | $0.06 | db.t2.small | $0.041 | $0.019 | $13.68 |
| 2 | 4 | $0.12 | db.t2.medium | $0.082 | $0.038 | $27.36 |
| 8 | 16 | $0.48 | db.r4.large | $0.29 | $0.190 | $136.80 |
| 16 | 32 | $0.96 | db.r4.xlarge | $0.58 | $0.38 | $273.60 |
| 32 | 64 | $1.92 | db.r4.2xlarge | $1.16 | $0.76 | $547.20 |
| 64 | 122 | $3.84 | db.r4.4xlarge | $2.32 | $1.52 | $1,094.40 |
| 128 | 244 | $7.68 | db.r4.8xlarge | $4.64 | $3.04 | $2,188.80 |
| 256 | 488 | $15.36 | db.r4.16xlarge | $9.28 | $6.08 | $4,377.60 |
As you can see, for sustained loads, the pricing for Aurora Serverless quickly becomes extremely expensive as compared to a single provisioned Aurora instance. However, according to the announcement, Aurora Serverless "creates an Aurora storage volume replicated across multiple AZs." It also seems to indicate that it relies on multiple nodes to handle requests, which suggests that the service automatically provides high-availability and failover via multiple AZs. If you follow AWS's recommendation to place "at least one Replica in a different Availability Zone from the Primary instance" to maximize availability, then the cost in the above chart would double for on-demand instances. This is a more fair comparison given the inherent high-availability nature of Aurora Serverless. The chart below assumes that each instance has a replica in a different availability zone.
| ACUs | Memory (GB) | Serverless/hr | Instance Type | Cost/hr | Diff/hour | Diff/month |
|---|---|---|---|---|---|---|
| 1 | 2 | $0.06 | db.t2.small | $0.082 | ($0.022) | ($15.84) |
| 2 | 4 | $0.12 | db.t2.medium | $0.164 | ($0.04) | ($31.68) |
| 8 | 16 | $0.48 | db.r4.large | $0.58 | ($0.10) | ($72.00) |
| 16 | 32 | $0.96 | db.r4.xlarge | $1.16 | ($0.20) | ($144.00) |
| 32 | 64 | $1.92 | db.r4.2xlarge | $2.32 | ($0.40) | ($288.00) |
| 64 | 122 | $3.84 | db.r4.4xlarge | $4.64 | ($0.80) | ($576.00) |
| 128 | 244 | $7.68 | db.r4.8xlarge | $9.28 | ($1.60) | ($1,152.00) |
| 256 | 488 | $15.36 | db.r4.16xlarge | $18.56 | ($3.20) | ($2,304.00) |
From this we can see significant cost savings, even if you maintained comparable capacity for 24 hours each day. Of course, the idea behind Aurora Serverless is to assume unpredictable workloads. If your application doesn't have extremely long periods of sustained load, only paying for occasional spikes in traffic would actually be significantly cheaper.
With regards to reserved instances, obviously there is a significant price difference. However, I always find it hard to plan database capacity (especially a year out), so buying reserved instances is always a crap shoot (for me anyway). However, the ability to buy "Reserved ACUs" would be a really interesting concept. That way I could prepay for HOURS of capacity at a discounted rate. Something to think about, Amazon. 😉
Autoscaling Aurora Serverless
A cornerstone of serverless architectures are their ability to provide continuous scaling. Aurora Serverless is designed to scale up based on the current load generated by your application. Your cluster will automatically scale ACUs up if either of the following conditions are met:
- CPU utilization is above 70% OR
- More than 90% of connections are being used
You cluster will automatically scale down if both of the following conditions are met:
- CPU utilization drops below 30% AND
- Less than 40% of connections are being used
Update May 2, 2019: According to the documentation, "There is no cooldown period for scaling up. Aurora Serverless can scale up whenever necessary, including immediately after scaling up or scaling down."
There is also a 3 minute cooldown period after a scale up operation occurs. I haven't fully tested this, but it seems to restrict the system from autoscaling more than once every 3 minutes. Similarly, However, there is a cooldown period of 15 minutes for scale down operations, meaning that your scaled capacity will be maintained for at least 15 minutes after a scale-up operation. This makes sense to avoid scaling down too quickly. After a scale down, there is a 310 second cooldown period before the cluster will scale down again.
IMPORTANT NOTE: As we saw in the setup, it's also possible to have your cluster automatically pause itself after a period of inactivity. If you are using your Aurora Serverless cluster in a production environment, I strongly suggest disabling this feature. It takes about 30 seconds to "unpause" a database, which is much too long for client-facing applications.
Aurora Serverless also introduces the concept of "scaling points", which refer to a point in time at which the database can safely initiate a scaling operation. The documentation specifies long-running queries, transactions, temporary tables, and table locks as reasons why it might not be able to scale. Aurora Serverless will try to scale the cluster five times before cancelling the operation.
Update May 2, 2019: "You can now choose to apply capacity changes even when a scaling point is not found. If you opt to forcibly apply capacity changes, active connections to your database may get dropped. This configuration could be used to more readily scale capacity of your Aurora Serverless DB clusters if your application is resilient to connection drops."
Manually Setting the Capacity
An extremely handy feature of Aurora Serverless is the ability to manually provision capacity for your cluster. This can be done via the console, AWS CLI, or the RDS API. If you are anticipating an increase in transactions, whether by detecting some type of leading indicator or preparing for a large batch operation, manually setting the ACUs allows you to quickly scale your cluster to handle the extra workload. Note that setting the capacity manually might drop existing connections if they prevent scaling operations. Once capacity is manually scaled, the same cooldown periods apply for autoscaling the cluster up and down.
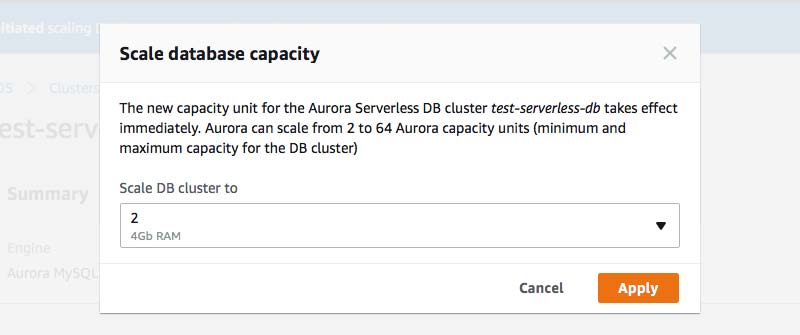
Details for modifying the capacity manually can be found in the API documentation here. The AWS Node.js SDK already provides support for manual scaling as well.
Max Connections
A major limitation of relational databases in serverless architectures is the maximum number of concurrent connections allowed by the database engine. While FaaS services like Lambda may scale infinitely (in theory anyway), massive spikes in volume can quickly saturate the number of available connections to the underlying database. There are ways to manage connections in serverless environments (also see Managing MySQL at Serverless Scale), but even with Aurora Serverless, this still appears to be a possible limiting factor.
AWS uses the following formula for generating the max_connections value for Aurora instances:
log( ( <<span class="">Instance Memory></span> * 1073741824) / 8187281408 ) * 1000 = <<span class="">Default Max Connections>
A db.r4.xlarge instance with 30.5 GB of memory for example would have a default max_connections value of 2,000.
log( (30.5 * 1073741824) / 8187281408 ) * 1000 = 2000
You can see the a list of default max_connections settings for provisioned Aurora instances here.
Aurora Serverless uses a similar formula based on memory allocation. I manually scaled a test cluster and ran select @@max_connections; after each operation to retrieve the actual value. The following chart outlines my results.
| ACUs | Memory (in GB) | Max Connections |
|---|---|---|
| 1 | 2 | 90 |
| 2 | 4 | 180 (up from 90) |
| 4 | 8 | 270 (up from 135) |
| 8 | 16 | 1,000 |
| 16 | 32 | 2,000 |
| 32 | 64 | 3,000 |
| 64 | 122 | 4,000 |
| 128 | 244 | 5,000 |
| 256 | 488 | 6,000 |
Update May 2, 2019: max_connections for 2 ACUs and 4 ACUs have now doubled.
If you compare this to the chart of provisioned instance values, you'll notice that they are essentially identical to their once they are at or above 8 ACUs, they are essentially identical to their corresponding instance types. However, with provisioned instances, you can manually change the max_connections value and squeeze a few more connections out of it. Aurora Serverless does not allow you to modify this value.
Provisioned clusters also allow for read replicas that can scale the number of available connections as well. Aurora Serverless does not allow for these.
Time to Scale
I ran a few tests to see how quickly the cluster would actually scale. Rather than simulating load (which I assume would have similar results), I manually scaled the cluster and measured the time it took for the max_connections value to change. I'm assuming that at that point, the new capacity was available for use. I also measured the time it took for the cluster status to change from "scaling-capacity" to "available".
| ACUs | Time to Capacity | Time to Completion |
|---|---|---|
| Up to 1 | 0:56 | 2:15 |
| Up to 4 | 0:48 | 2:15 |
| Up to 8 | 1:30 | 3:00 |
| Up to 16 | 0:45 | 1:37 |
| Up to 32 | 0:50 | 1:45 |
| Up to 64 | 1:00 | 1:40 |
| Up to 128 | 1:25 | 2:05 |
| Up to 256 | 2:30 | 3:45 |
| Down to 2 | 0:35 | 2:21 |
| Down to 1 | 1:10 | 2:56 |
My tests showed most of the scaling operations taking less than a minute. Assuming similar performance for autoscaling operations, this would seem to be adequate for handling steadily increasing or potentially even sudden traffic bursts.
Update May 2, 2019: I reran the scaling tests and the numbers were all very similar to my original results. You can expect approximately 1 minute to scale capacity, and another minute for the operation to fully complete.
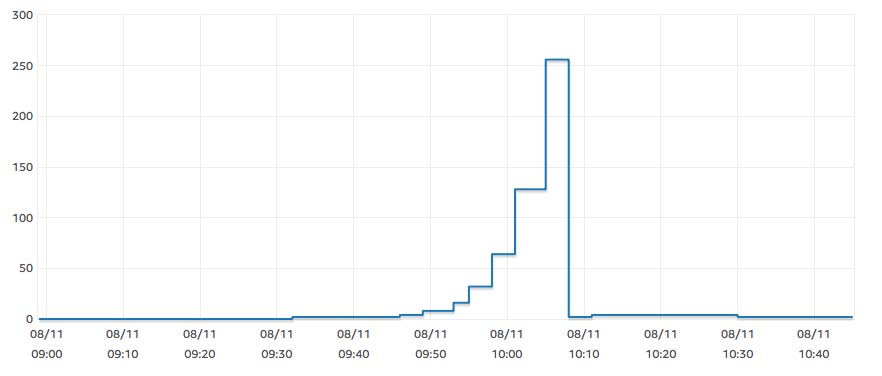
Monitoring
CloudWatch provides all the same metrics for Aurora Serverless that it does for provisioned clusters. In addition, CloudWatch allows you to monitor the capacity allocated to your cluster using the ServerlessDatabaseCapacity metric. This would make for a great alarm.
Final Thoughts
So far I'm very impressed by Aurora Serverless and the new capabilities it introduces. I also think that most of the limitations, such as IAM authentication, S3 integration, and Lambda triggers will eventually make their way into the platform. But even the lack of those features (which didn't even exist until AWS introduced them with Aurora), isn't enough to outweigh the tremendous value that Aurora Serverless provides. If you are a PostgreSQL shop (this is supposedly coming soon), or you really need MySQL 5.7, then you might need to wait, but otherwise, this could be the new way to do relational databases at scale.
I need to run some additional tests to see how well it plays with Lambda, especially with regards to the connection limitation, but after playing with this for a few months, I'm inclined to start using it in production. I already have several clusters that are over provisioned to handle periodic traffic spikes. If this scales as expected, it very well could be the silver bullet I've been looking for. 🤔
Update May 2, 2019: I have been running Aurora Serverless clusters in production for several months now and haven't had any problems with them. As far as the max_connections issue is concerned, I have been using the serverless-mysql package without issue.
Are you planning on using Aurora Serverless? Let me know in the comments and describe the problem you plan on solving with it.