Aurora Serverless Data API: An (updated) First Look
AWS announced support for the Aurora Serverless Data API, an HTTP API for querying relational databases from serverless apps. But is it ready for primetime?
Update June 5, 2019: The Data API team has released another update that adds improvements to the JSON serialization of the responses. Any unused type fields will be removed, which makes the response size 80+% smaller.
Update June 4, 2019: After playing around with the updated Data API, I found myself writing a few wrappers to handle parameter formation, transaction management, and response formatting. I ended up writing a full-blown client library for it. I call it the "Data API Client", and it's available now on GitHub and NPM.
Update May 31, 2019: AWS has released an updated version of the Data API (see here). There have been a number of improvements (especially to the speed, security, and transaction handling). I've updated this post to reflect the new changes/improvements.
On Tuesday, November 20, 2018, AWS announced the release of the new Aurora Serverless Data API. This has been a long awaited feature and has been at the top of many a person's #awswishlist. As you can imagine, there was quite a bit of fanfare over this on Twitter.
Ya'll been waiting eagerly for this one! Access an Aurora Serverless database via HTTPS API: https://t.co/OUkqA8U3Y1 still in beta, but will change the way you think about #awsLambda and relational databases! #serverless
— Chris Munns (@chrismunns) November 21, 2018
Obviously, I too was excited. The prospect of not needing to use VPCs with Lambda functions to access an RDS database is pretty compelling. Think about all those cold start savings. Plus, connection management with serverless and RDBMS has been quite tricky. I even wrote an NPM package to help deal with the max_connections issue and the inevitable zombies 🧟♂️ roaming around your RDS cluster. So AWS's RDS via HTTP seems like the perfect solution, right? Well, not so fast. 😞 (Update May 31, 2019: There have been a ton of improvements, so read the full post.)
Update May 31, 2019: The Data API is now GA (see here)
Before I go any further, I want to make sure that I clarify a few things. First, the Data API is (still) in BETA, so this is definitely not the final product. Second, AWS has a great track record with things like this, so I'm betting that this will get a heck of lot better before it reaches GA. And finally, I am a huge AWS fan (and I think they know that 😉), but this first version is really rough, so I'm not going to pull any punches here. I can see this being a complete #gamechanger once they iron out the kinks, so they definitely can benefit from constructive feedback from the community.
Enabling the Data API
Before we dive into performance (honestly I want to avoid telling you about it for as long as possible), let's look at the set up. There is an AWS guide that tells you how to switch on the Data API. The guide is pretty thin right now, so I'll give you basics. Update May 31, 2019: The documentation has gotten much better and can walk you through the set up.
NOTE: The Data API only works with Aurora Serverless clusters AND it is only available in the us-east-1 region. Update May 31, 2019: Data API is available in US East (N. Virginia), US East (Ohio), US West (Oregon), Asia Pacific (Tokyo), and Europe (Ireland) Regions. If you haven't played around with Aurora Serverless yet, check out my post Aurora Serverless: The Good, the Bad and the Scalable.
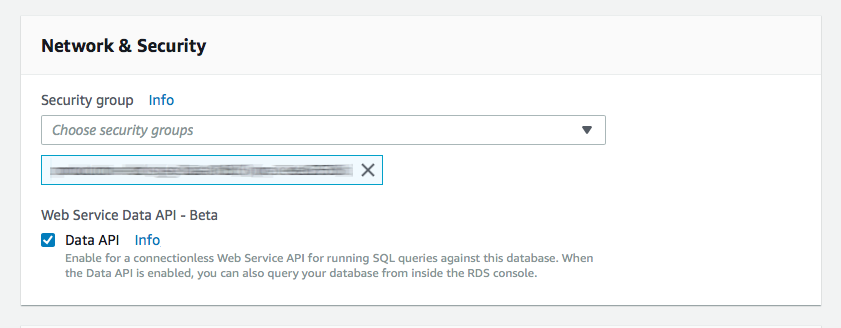
You need to modify your Aurora Serverless cluster by clicking "ACTIONS" and then "Modify Cluster". Just check the Data API box in the Network & Security section and you're good to go. Remember that your Aurora Serverless cluster still runs in a VPC, even though you don't need to run your Lambdas in a VPC to access it via the Data API.
Next you need to set up a secret in the Secrets Manager. 🤫 This is actually quite straightforward. User name, password, encryption key (the default is probably fine for you), and select the database you want to access with the secret.
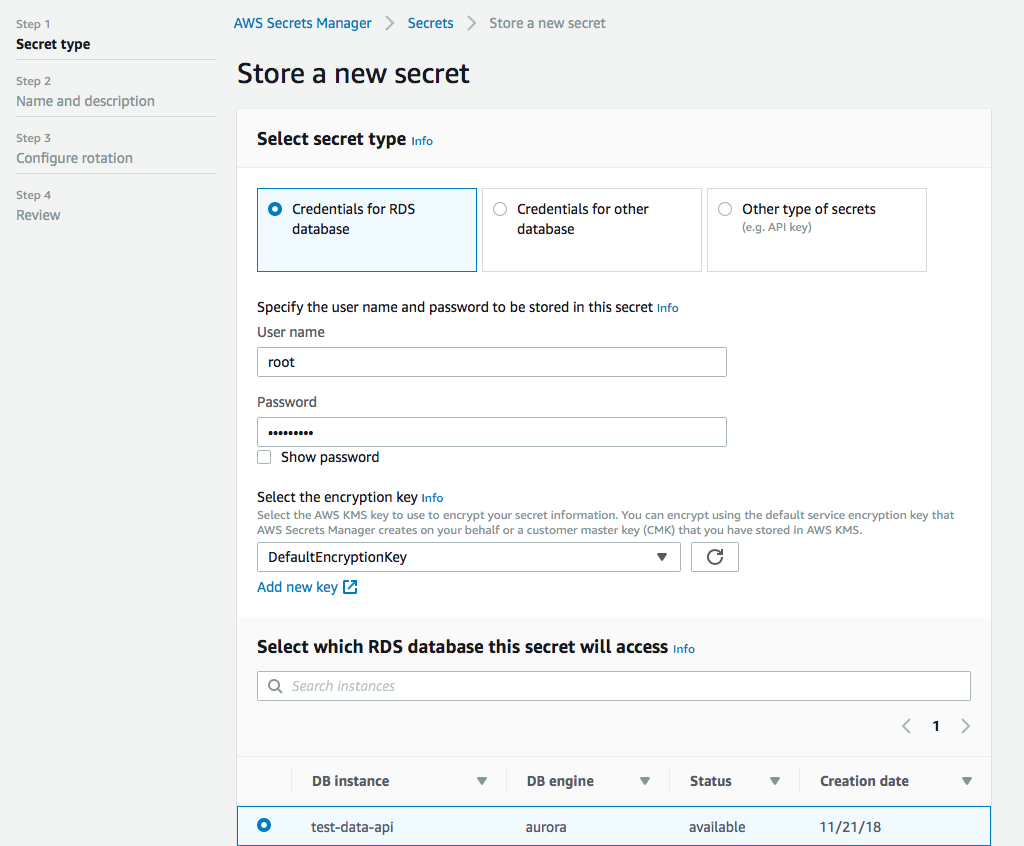
Next we give it a name, this is important, because this will be part of the arn when we set up permissions later. You can give it a description as well so you don't forget what this secret is about when you look at it in a few weeks.
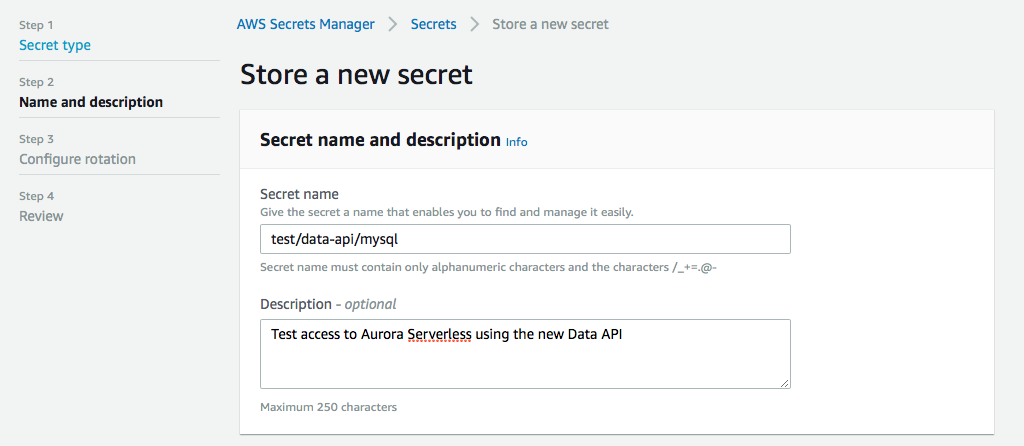
You can then configure your rotation settings, if you want, and then you review and create your secret. Then you can click on your newly created secret and grab the arn, we're gonna need that next.
Using the AWS SDK's RDSDataService
If you were looking for this in the AWS guide for the Data API, you probably won't find it. As of this writing it isn't in there. Update May 31, 2019: It's sort of in the documentation now. You may have stumbled across the SDK docs and found Class: AWS.RDSDataService. But there are a bunch of options that bury the lead. Right now we just care about executeSql(). Here is the snippet from the docs:
OLD WAY:
1var params = {2 awsSecretStoreArn: 'STRING_VALUE', /* required */3 dbClusterOrInstanceArn: 'STRING_VALUE', /* required */4 sqlStatements: 'STRING_VALUE', /* required */5 database: 'STRING_VALUE',6 schema: 'STRING_VALUE'7};8rdsdataservice.executeSql(params, function(err, data) {9 if (err) console.log(err, err.stack); // an error occurred10 else console.log(data); // successful response11});
Update May 31, 2019: executeSql() has been deprecated in favor of executeStatement() and batchExecuteStatement(). Your snippet looks like this:
1var params = {2 resourceArn: 'STRING_VALUE', /* required */3 secretArn: 'STRING_VALUE', /* required */4 sql: 'STRING_VALUE', /* required */5 continueAfterTimeout: true || false,6 database: 'STRING_VALUE',7 includeResultMetadata: true || false,8 parameters: [9 {10 name: 'STRING_VALUE',11 value: {12 blobValue: new Buffer('...') || 'STRING_VALUE' /* Strings will be Base-64 encoded on your behalf */,13 booleanValue: true || false,14 doubleValue: 'NUMBER_VALUE',15 isNull: true || false,16 longValue: 'NUMBER_VALUE',17 stringValue: 'STRING_VALUE'18 }19 },20 /* more items */21 ],22 schema: 'STRING_VALUE',23 transactionId: 'STRING_VALUE'24};25rdsdataservice.executeStatement(params, function(err, data) {26 if (err) console.log(err, err.stack); // an error occurred27 else console.log(data); // successful response28});
As you can see, lots of new parameters have been added here. More detail to follow.
Easy enough. Looks like we're going to need that arn from our secret we just created, the arn of our Aurora Serverless cluster (you can find that in the cluster details), and then our SQL statements. Before we take this out for a drive, we need some data to query. I set up a database with a single table and started by inserting five rows:
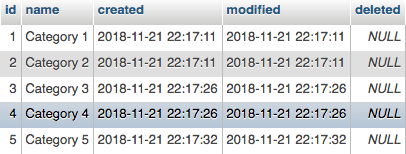
Now let's set up a simple Lambda function and give it a try.
OLD WAY:
1const AWS = require('aws-sdk')2const RDS = new AWS.RDSDataService()34exports.test = async (event, context) => {56 try {78 const params = {9 awsSecretStoreArn: 'arn:aws:secretsmanager:us-east-1:XXXXXXXXX:secret:test/data-api/mysql-JchWT1',10 dbClusterOrInstanceArn: 'arn:aws:rds:us-east-1:XXXXXXXXXXX:cluster:test-data-api',11 sqlStatements: `SELECT * FROM cats`,12 database: 'test_data_api'13 }1415 let data = await RDS.executeSql(params).promise()1617 console.log(JSON.stringify(data, null, 2))18 19 return 'done'2021 } catch(e) {22 console.log(e)23 }24}
Updated May 31, 2019: Using the executeStatement() method instead here. Notice that you can now use named parameters, which is pretty cool.
1const AWS = require('aws-sdk')2const RDS = new AWS.RDSDataService()34exports.test = async (event, context) => {56 try {78 const params = {9 awsSecretStoreArn: 'arn:aws:secretsmanager:us-east-1:XXXXXXXXX:secret:test/data-api/mysql-JchWT1',10 dbClusterOrInstanceArn: 'arn:aws:rds:us-east-1:XXXXXXXXXXX:cluster:test-data-api',11 sql: `SELECT * FROM cats WHERE id = :id`,12 parameters: [13 {14 name: 'id',15 value: {16 "longValue": 117 }18 }19 ],20 database: 'test_data_api'21 }2223 let data = await RDS.executeStatement(params).promise()2425 console.log(JSON.stringify(data, null, 2))26 27 return 'done'2829 } catch(e) {30 console.log(e)31 }32}
Notice above that I'm using async/await, so I'm taking advantage of the .promise() method that AWS provides to promisify their services. You can use callbacks if you really want to. But I wouldn't. 😉
I used the Serverless framework to publish this to AWS, but those are just details. Let's give this a try and see what happens when we publish and run it.
Error: AWS.RDSDataService is not a constructor
Hmm, looks like the version of aws-sdk running on Lambdas in us-east-1 isn't the latest version. Let's repackage our function with the aws-sdk and try it again.
Updated May 31, 2019: AWS.RDSDataService is included in the SDK available from Lambda. So no need to include the dependency anymore.
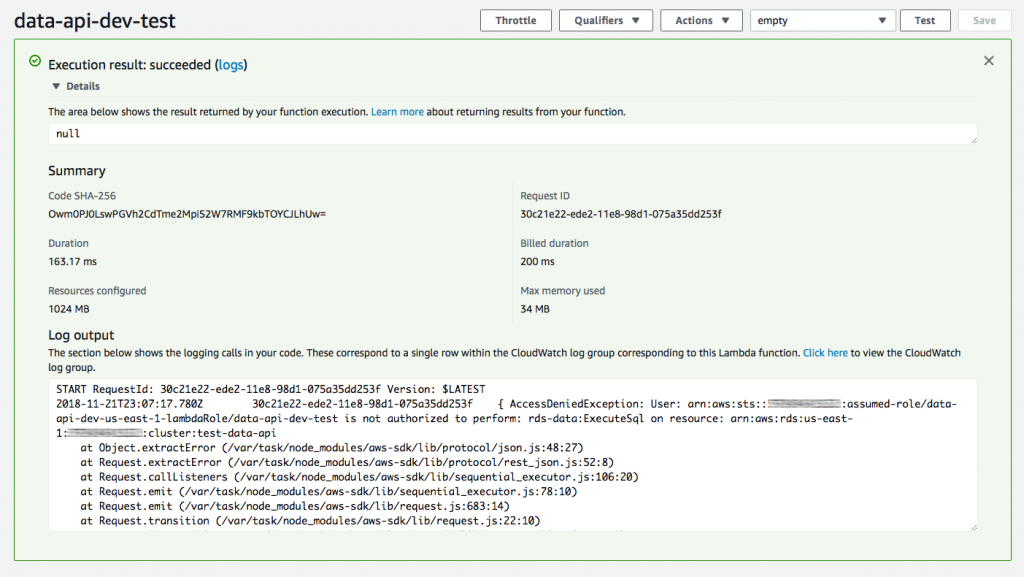
Okay, looks like we need some IAM permissions. Let add those:
Update May 31, 2019: According to the documentation, here are the minimum permissions required to use the DATA API. However, from your Lambda function, most are not necessary. I've note them inline as "unnecessary."
1{2 "Version": "2012-10-17",3 "Statement": [4 {5 "Sid": "SecretsManagerDbCredentialsAccess",6 "Effect": "Allow",7 "Action": [8 "secretsmanager:GetSecretValue",9 "secretsmanager:PutResourcePolicy", // unnecessary10 "secretsmanager:PutSecretValue", // unnecessary11 "secretsmanager:DeleteSecret", // unnecessary12 "secretsmanager:DescribeSecret", // unnecessary13 "secretsmanager:TagResource" // unnecessary14 ],15 "Resource": "arn:aws:secretsmanager:*:*:secret:rds-db-credentials/*"16 },17 {18 "Sid": "RDSDataServiceAccess",19 "Effect": "Allow",20 "Action": [21 "secretsmanager:CreateSecret", // unnecessary22 "secretsmanager:ListSecrets", // unnecessary23 "secretsmanager:GetRandomPassword", // unnecessary24 "tag:GetResources", // unnecessary25 "rds-data:BatchExecuteStatement",26 "rds-data:BeginTransaction",27 "rds-data:CommitTransaction",28 "rds-data:ExecuteStatement",29 "rds-data:RollbackTransaction"30 ],31 "Resource": "*"32 }33 ]34}
NOTE: The permission below are no longer accurate. Use the ones above. Keeping this here for the history.
1# Not relevant as of May 31, 20192iamRoleStatements:3 - Effect: "Allow"4 Action:5 - "rds-data:ExecuteSql"6 Resource: "arn:aws:rds:us-east-1:XXXXXXXXX:cluster:test-data-api"
And try it again.
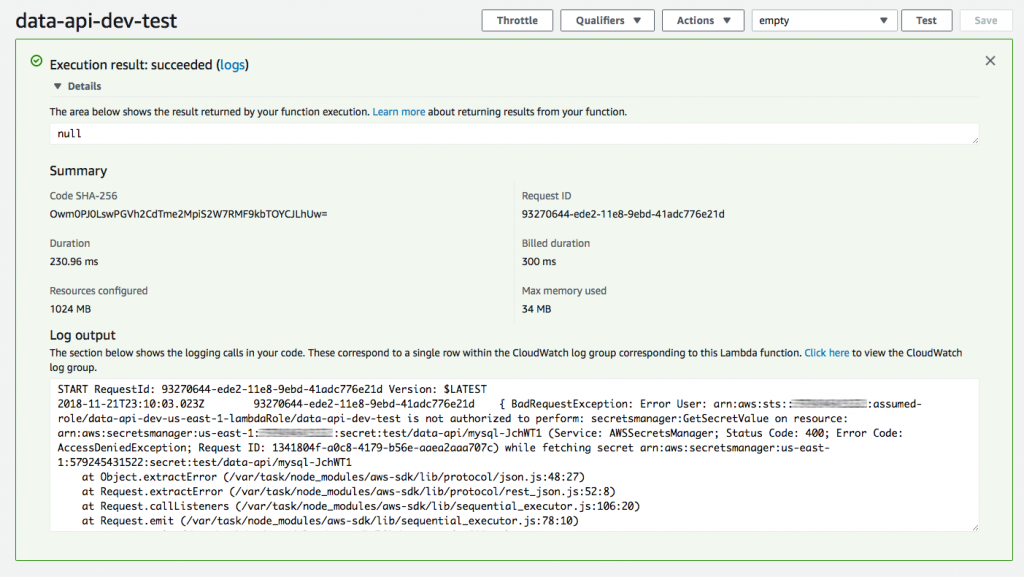
Crap. Okay, we need some more IAM permission:
1# Not relevant as of May 31, 20192iamRoleStatements:3 - Effect: "Allow"4 Action:5 - "rds-data:ExecuteSql"6 Resource: "arn:aws:rds:us-east-1:XXXXXXXXXX:cluster:test-data-api"7 - Effect: "Allow"8 Action:9 - "secretsmanager:GetSecretValue"10 Resource: "arn:aws:secretsmanager:us-east-1:XXXXXXXXXX:secret:test/data-api/*"
Okay, now we should be good to go! Let's run it again.
Update May 31, 2019: Here is the new response, compare to the old one below it.
Update June 5, 2019: This response is even smaller now that they removed the unused type fields from the response.
1{2 "columnMetadata": [3 {4 "arrayBaseColumnType": 0,5 "isAutoIncrement": true,6 "isCaseSensitive": false,7 "isCurrency": false,8 "isSigned": false,9 "label": "id",10 "name": "id",11 "nullable": 0,12 "precision": 10,13 "scale": 0,14 "schemaName": "",15 "tableName": "cats",16 "type": 4,17 "typeName": "INT UNSIGNED"18 },19 {20 "arrayBaseColumnType": 0,21 "isAutoIncrement": false,22 "isCaseSensitive": false,23 "isCurrency": false,24 "isSigned": false,25 "label": "name",26 "name": "name",27 "nullable": 1,28 "precision": 100,29 "scale": 0,30 "schemaName": "",31 "tableName": "cats",32 "type": 12,33 "typeName": "VARCHAR"34 },35 {36 "arrayBaseColumnType": 0,37 "isAutoIncrement": false,38 "isCaseSensitive": false,39 "isCurrency": false,40 "isSigned": false,41 "label": "created",42 "name": "created",43 "nullable": 0,44 "precision": 19,45 "scale": 0,46 "schemaName": "",47 "tableName": "cats",48 "type": 93,49 "typeName": "TIMESTAMP"50 },51 {52 "arrayBaseColumnType": 0,53 "isAutoIncrement": false,54 "isCaseSensitive": false,55 "isCurrency": false,56 "isSigned": false,57 "label": "modified",58 "name": "modified",59 "nullable": 0,60 "precision": 19,61 "scale": 0,62 "schemaName": "",63 "tableName": "cats",64 "type": 93,65 "typeName": "TIMESTAMP"66 },67 {68 "arrayBaseColumnType": 0,69 "isAutoIncrement": false,70 "isCaseSensitive": false,71 "isCurrency": false,72 "isSigned": false,73 "label": "deleted",74 "name": "deleted",75 "nullable": 1,76 "precision": 19,77 "scale": 0,78 "schemaName": "",79 "tableName": "cats",80 "type": 93,81 "typeName": "TIMESTAMP"82 }83 ],84 "numberOfRecordsUpdated": 0,85 "records": [86 [87 {88 "longValue": 189 },90 {91 "stringValue": "Category 1"92 },93 {94 "stringValue": "2018-11-21 22:17:11.0"95 },96 {97 "stringValue": "2018-11-21 22:17:11.0"98 },99 {100 "stringValue": null101 }102 ],103 [104 {105 "longValue": 2106 },107 {108 "stringValue": "Category 2"109 },110 {111 "stringValue": "2018-11-21 22:17:11.0"112 },113 {114 "stringValue": "2018-11-21 22:17:11.0"115 },116 {117 "stringValue": null118 }119 ],120 [121 {122 "longValue": 3123 },124 {125 "stringValue": "Category 3"126 },127 {128 "stringValue": "2018-11-21 22:17:26.0"129 },130 {131 "stringValue": "2018-11-21 22:17:26.0"132 },133 {134 "stringValue": null135 }136 ],137 [138 {139 "longValue": 4140 },141 {142 "stringValue": "Category 4"143 },144 {145 "stringValue": "2018-11-21 22:17:26.0"146 },147 {148 "stringValue": "2018-11-21 22:17:26.0"149 },150 {151 "stringValue": null152 }153 ],154 [155 {156 "longValue": 5157 },158 {159 "stringValue": "Category 5"160 },161 {162 "stringValue": "2018-11-21 22:17:32.0"163 },164 {165 "stringValue": "2018-11-21 22:17:32.0"166 },167 {168 "stringValue": null169 }170 ]171 ]172}
Old response:
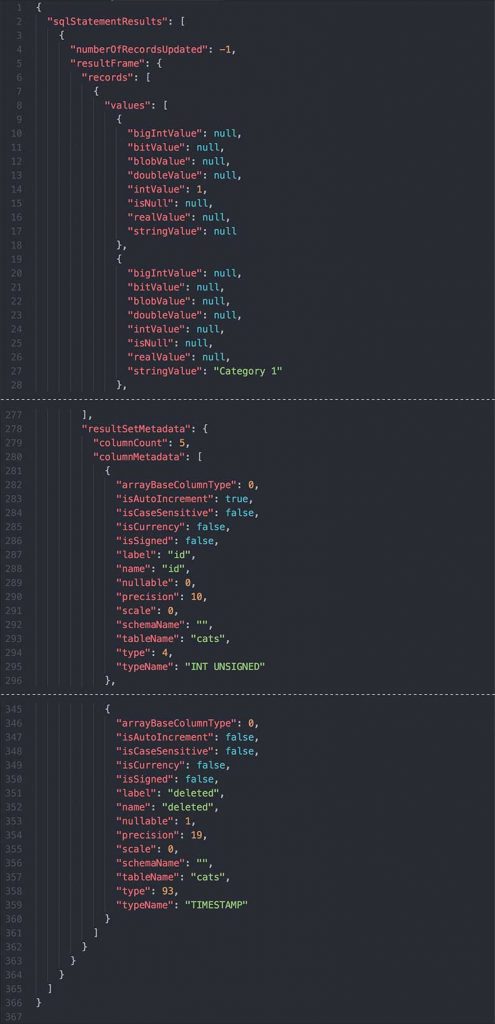
This is querying our tiny little table of 5 rows with 5 columns with very little data. The Data API returned this monstrous JSON response that was over 11 KBs and took 228ms to run! Update May 31, 2019: The response is smaller now (just over 7 KBs), but still quite heavy. Update June 5, 2019: The JSON serialization of the response has been improved, so empty type fields are removed from the response! The performance has improved a bit as well. I'm now getting an average of sub 100ms when querying just a few rows. Okay, we can't put this off any longer. Let's look at the performance.
Data API Performance Metrics
Alright, so let's just rip off the bandaid here. The performance is not good great. I added a few more rows to the table and ran a comparison of the Data API versus a MySQL connection (using the mysql package) in a VPC. Here's what I got:

Update May 31, 2019: The original results above still apply for the native MySQL connection. For the DATA API results, the returned data is much smaller (though still more than necessary), but the speed improvement is HUGE! There seems to be a "cold start" like penalty for the first query, but subsequent queries are near or sub 100ms. Much better than before.
Update June 5, 2019: The smaller response sizes help reduce the latency a bit, but if you enable HTTP Keep Alive, subsequent queries (and even reused connections), have some really good latencies.

This was the same query run against the same cluster and table. You can see that the Data API took 204 ms ~100ms (updated) to query and return 175 rows versus the MySQL connection that only took 5 ms. Something to note here is that the 5 ms was after the function was warm and the initial MySQL connection was established. Obviously VPCs have a higher cold start time, so the first query will be a bit slower (about 150 ms plus the cold start). After that though, the speed is lightning fast. However, the Data API averaged over 200 ms every time approximately 100ms every time (updated) it ran, warm or not.
Also, the size of the responses were radically different. The Data API returned another monster JSON blob weighing in at 152.5 KBs 75 KBs (updated). The direct MySQL connection returned essentially the same data in under 30 KBs. I'm sure there will be optimizations in the future that will allow us to reduce the size of this response. There is a bunch of stuff in there that we don't need.
Update May 31, 2019: A new parameter called includeResultMetadata that allows you to suppress the columnMetadata field in the response. Couple of things to note here. 1) this doesn't really reduce the response size much, and 2) the results themselves are not mapped to column names, so without the columnMetadata, you need to map you're columns to array index numbers. So, not super useful in my opinion. 🤷♂️
Next I tried some INSERTs. I ran 10 simple INSERT statements with just one column of data. Once again I compared the Data API to a MySQL connection in a VPC.
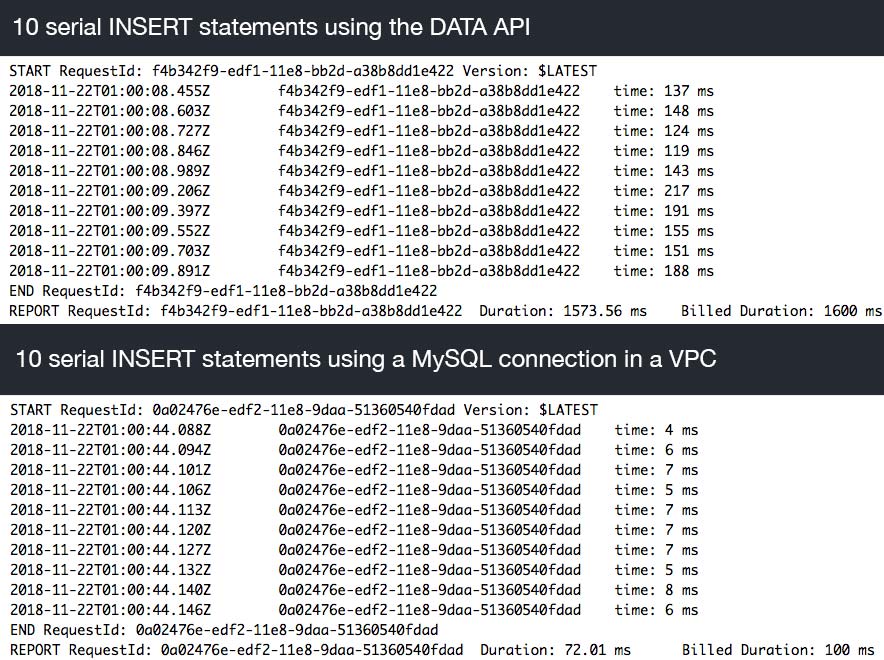
Update May 31, 2019: I reran these test and the performance was improved quite a bit. Each insert took anywhere from 60ms to 150ms.
Once again, the direct MySQL connection blew away the Data API in terms of response times. Same caveats as before with these being warm functions, so the MySQL connection was already established and being reused. But as you can see, each Data API call suffers from the same high latency as the one before it. Which means, as is to be expected with an HTTP endpoint, that there is no performance gain by reusing the same const RDS = new AWS.RDSDataService() instance.
Another thing to note, however, is that the performance wasn't impacted by more complex queries or larger data retrievals. The underlying MySQL engine performs as expected, so if AWS can fix this roundtrip latency issue, then hopefully all these performance issues go away.
Update May 31, 2019: There is a new method named batchExecuteStatement() that lets you use parameterSets to reuse the same query for multiple inserts. The benefit here is that you only need to make ONE HTTP call. I ran a few tests (inserting 10 records), and as expected, the performance was similar to a single query, around 100ms. Still not great, but definitely more efficient than sending them in one by one.
Tweaking the knobs
I've been waiting for HTTP endpoints for RDS for a loooong time, so I didn't want to let a few bad experiments ruin my day. I decided to turn some knobs to see if that would affect the performance. First thing I did was turn up the memory on my function. Higher memory equals higher CPU and throughput (I think), so I gave that a try. Unfortunately, there was no impact.
Then I thought, maybe if I beef up the database cluster, it might shave off some milliseconds. This was obviously wishful thinking, but I tried it anyway. I cranked up my cluster to 64 ACUs and... nothing. 😖 Oh well, it was worth a shot.
Transaction Support! (added May 31, 2019)
The new version of the Data API has added Transaction Support! The process is a little more complicated than working with native MySQL, but it appears to work really well. From the docs:
1var params = {2 resourceArn: 'STRING_VALUE', /* required */3 secretArn: 'STRING_VALUE', /* required */4 database: 'STRING_VALUE',5 schema: 'STRING_VALUE'6};7rdsdataservice.beginTransaction(params, function(err, data) {8 if (err) console.log(err, err.stack); // an error occurred9 else console.log(data); // successful response10});
You need to call beginTransaction and wait for a transactionId to be returned. It looks like this:
1{ 2 transactionId: 'AQC5SRDIm6Bu8oYabo1aiOKkjFsyhGe+AuBSFF2DFWELyW1nQGZEcsjQk1V5wDnissZSucD4bc6GGCILfXp9MCkOelFJQgU2iWfkccut82pQraUxYVKym7yhpSSnKDW4FLkE2mwm7t3BSQNl5HlfTemiLWwJ7D89kB7IcUgttVIBo8ZHXP/WORU='3}
You then include this with all of your executeStatement calls and then call either commitTransaction() or rollbackTransaction(). Then you get a nice little message like this:
1{ transactionStatus: 'Transaction Committed' }
As you've probably surmised, transactions handled this way require multiple HTTP calls in order to complete, which based on the latency, probably means you don't want to run them for synchronous operations. Here are some other helpful tips from the documentation:
- A transaction can run for a maximum of 24 hours. A transaction is terminated and rolled back automatically after 24 hours.
- A transaction times out if there are no calls that use its transaction ID in three minutes. If a transaction times out before it's committed, it's rolled back automatically.
- If you don't specify a transaction ID, changes that result from the call are committed automatically.
Also note that, by default, calls timeout and are terminated in one minute if it's not finished processing. You can use the continueAfterTimeout parameter to continue running the SQL statement after the call times out.
What about security?
Update May 31, 2019: Good news! executeStatement and batchExecuteStatement still accepts strings, but it errors if you include multiple statements. You can also used named parameters now, so be sure to do that so all your values are escaped for you!
So another thing I noticed when I first looked at the docs, is that the sqlStatements parameter expects a string. Yup, a plain old string. Not only that, you can separate MULTIPLE SQL statements with semicolons! Did I mention this parameter only accepts a string? If you're not sure why this is a big deal, read up on SQL Injection or have a look at my Securing Serverless: A Newbie's Guide.
Don't want to listen to me? Fine, but you should definitely take Ory Segal's advice. He's one of those people that knows what he's talking about.
The new #AWS #aurora #serverless data API is uber cool, just do everyone a favor, and before you run any SQL statements, run them through a query formatter/escaping library. If you're using node, check out the 'mysql' package, and use mysql.format() method.
— - 𝙾𝚛𝚢 𝚂𝚎𝚐𝚊𝚕 - (@orysegal) November 21, 2018
But seriously, this is a huge security issue if you aren't properly escaping values. The mysql package he referenced actually disables multiple statements by default because they can be so dangerous. Let's hope that some additional features are added that will do some of the escaping for us.
Some final thoughts
This thing is still in beta~~, and it really shows~~. There is a lot of work to be done, but I have faith that the amazing team at AWS will eventually turn the Data API in to pure gold. The latency here seems to be entirely with the overhead of setting up and tearing down the VPC connections behind the scenes. DynamoDB is HTTP-based and has single digit latency, so I'm guessing that HTTP isn't the major issue.
Anyway, here are a few of the things that I'd like to see before the Data API goes GA:
- Increased performance: I'd much rather suffer through a few cold starts now and then to enjoy 5 ms queries than to suffer through 200 ms for every query. Right now, these speeds make it unusable for synchronous use cases. Update May 31, 2019: I still feel this way for synchronous use cases, but there could be some caching improvements to make this viable.
- Response formatting: I get the value in returning the different data types, but it is overkill for 99% of queries. Besides simplifying that (and getting the JSON size down a bit), optionally returning the column information would be helpful too. I don't need it most of the time. Update May 31, 2019: There is still way too much data coming over the wire. They need to cut this down.
Prepared queries: The currentUpdate May 31, 2019: I doubt I was the only one who suggested this, but it looks like they implemented this with named parameters. Very cool.sqlStatementsparameter is too dangerous. I know developers should take some responsibility here, but needing another library to escape SQL queries is unnecessary overhead. Some simply features of themysqlpackage (maybe a newparamsfield that excepts an array and replaces?in the queries) would go a long way.Disable multiple statements by default: Having the ability to send multiple queries is really powerful (especially over HTTP), but it's also super dangerous. It would be safer if you needed to expressly enable multiple statement support. Even better, require multiple statements to be sent in as an array.Update May 31, 2019: They did this too! Well, without my array idea. 😐- IAM Role-based access: The secrets manager thing is okay, but it would be better if we could access Aurora Serverless using just the IAM role. I know that Aurora Serverless doesn't support that yet, but this would be a helpful addition.
I have to say that I really love this concept. Yes, I~~'m~~ was underwhelmed by the initial implementation~~, but again, it is still very early~~. When (and I'm confident that it is a when, not an if) the AWS team works through these issues, this will help dramatically with serverless adoption. There are still plenty of use cases for RDBMS, so making it easier to use them is a huge win for serverless.
Finally, since I've offered a lot of criticism, I figured I'd end this on a bit of a positive note. The latency is a killer for synchronous applications, BUT, even in its current state, I can see this being extremely useful for asynchronous workflows. If you are running ETLs, for example, firing off some bulk loads into your reporting database without needing to run the Lambdas in a VPC would be quite handy.
Update May 31, 2019: I'm really impressed by the updates that have been made. I do want to reiterate that this isn't an easy problem to solve, so I think the strides they've made are quite good. I'm not sure how connection management works under the hood, so I'll likely need to experiment with that a bit to measure concurrent connection performance.
What are your thoughts on the new (and improved) Aurora Serverless Data API? I'd love to know what you think. Hit me up on Twitter or share your thoughts in the comments below.