Throttling Third-Party API calls with AWS Lambda
All third-party APIs have limits, so how do we handle them with serverless applications that have a much higher scale? This post explores the issue and offers a solution.
In the serverless world, we often get the impression that our applications can scale without limits. With the right design (and enough money), this is theoretically possible. But in reality, many components of our serverless applications DO have limits. Whether these are physical limits, like network throughput or CPU capacity, or soft limits, like AWS Account Limits or third-party API quotas, our serverless applications still need to be able to handle periods of high load. And more importantly, our end users should experience minimal, if any, negative effects when we reach these thresholds.
There are many ways to add resiliency to our serverless applications, but this post is going to focus on dealing specifically with quotas in third-party APIs. We'll look at how we can use a combination of SQS, CloudWatch Events, and Lambda functions to implement a precisely controlled throttling system. We'll also discuss how you can implement (almost) guaranteed ordering, state management (for multi-tiered quotas), and how to plan for failure. Let's get started!
FUN FACT: Third-party APIs can't scale infinitely either, so most (if not all) put some sort of quota on the number of API calls that you can make. Many use daily quotas, but most use a much more granular per second or per minute model. This allows them to throttle requests to their backend systems, but potentially leaves us with a bunch of
429 Too Many Requestserrors.
Identifying the problem
Before we get to the solution, let's identify the root of the problem first. In more "traditional" applications, we can throttle calls to third-party APIs in a number of ways. A monolithic design would likely maintain state, allowing you to simply delay API calls until an internal counter indicated some passage of time. Even in distributed applications, you could use Redis, or some other caching mechanism, to share state across an entire cluster. These types of architectures allow for persistent connections, meaning you could provide highly isolated, atomic transactions that would allow nodes to coordinate quotas.
With serverless applications, this gets a bit more tricky. Lambda functions do not maintain state across concurrent executions. You can reuse database connections and global variables IF a warm container is invoked, but there is no guarantee that a container will be reused, or how long it will last. The concurrency model of Lambda functions invokes a new container for every concurrent user, which means if you have 100 users accessing a Lambda function, then 100 separate instances of that Lambda function will be created. No shared state, and no simple way to coordinate API calls to our third-party APIs.
In a previous post, How To: Use SNS and SQS to Distribute and Throttle Events, I discussed using SQS queues as a way to throttle calls to downstream systems. This works great when you are trying to limit throughput to "less-than-infinitely-scalable" systems (such as RDBMS with max_connections and read/write throughput limits), but there are two major problems with this when dealing with third-party API quotas.
First, concurrency (as a solution discussed in the other post), has no effect on frequency. This means that even if you have a low concurrency set when chewing through items in a queue, there is no guarantee to how quickly they will be processed. If the processing happens quickly, we'll likely exceed our per second or per minute quotas. If the processing happens too slowly (e.g. each API call takes 2 seconds to complete, but our quota is 1 call per second), then we are not fully utilizing our available quota and potentially creating a backlog in our own system.
The second issue has to do with coordination. When Lambda functions are subscribed to SQS Queues, AWS manages an SQS poller that polls for messages and then delivers them synchronously to your functions. Again, this is great for the right use case, but since these functions are stateless, they have no way of knowing how many quota units you have left, when the last API call was made, or if any multi-tiered quotas (like per day or per month limits) have been reached. Also, SQS subscriptions from Lambda don't support FIFO (first-in, first-out) queues. If ordering is important, then this method isn't going to work for you.
**A word about synchronicity
**The methods we're discussing in this post require the use of asynchronous invocations. This means that we are invoking functions using events and are only waiting for confirmation that the event was received. We are NOT waiting for the functions to execute and respond. Whenever possible, you should try to minimize (or eliminate) synchronous calls to other components, especially if end users are waiting for a response.
Exploring possible solutions
There are a number of ways that we can potentially solve this problem. The first option (and a likely AWS suggestion), would be to use Step Functions. We could create a state machine that used a Lambda function to poll our SQS queue and then use a series of parallel tasks and delays to orchestrate other Lambda functions to perform our throttled API calls (maybe something like this). But there are a number of problems with this approach.
First, it would be insanely expensive. At $0.025 per 1,000 transitions (and with likely several transitions per API call), this solution would become cost prohibitive. Second, it would be a bit complicated. Step functions support sending messages to SQS queues, but not receiving them. In this case, you'd still have to build a Lambda polling function that would get messages and then send them to the next state. The for looping and delays would also be a bit unwieldily and not easy to wrap your head around. Finally, Step Functions have a lot of limits, especially when it comes to throttling certain actions. Some of these limits can be increased, but managing these for something with high-throughput, like API calls, IMO, adds unnecessary complexity.
Another option would be to add shared state to our Lambda functions. This could be accomplished using a similar approach to our "traditional" distributed system. We could set up an ElastiCache cluster and connect to it every time a new Lambda function was invoked. This would allow us to store and share state across invocations, giving us access to all the data we'd need to delay an API call until there was available quota. Reused connections are extremely fast, so if we don't mind a slightly longer cold start time, the p99 latency would be barely noticeable.
This option clearly adds a "non-serverless" component and another thing to manage (and pay for). Granted, ElastiCache is pretty much managed for you, but we also add the complexity (and NAT cost) of using a VPC. Another "serverless" option (without a VPC) would be to use DynamoDB as our caching layer. This would work perfectly fine, but we would likely need to configure very high read and write capacities to handle the transactions from high volume throughputs. This could get very expensive.
There is another major issue with the two caching solutions above: we could be paying for our functions to wait. Delays with Step Functions delay invocation, delays in our Lambda functions delay execution. This means that for every 100ms that our Lambda functions are sleeping, we are paying for that execution time. I wrote a post that discussed how not to overpay when waiting on remote API calls that points out the cost differences between memory configuration and performance for non-compute intensive tasks. Just as we don't want to pay to wait for some other system to complete its processing, we also don't want to pay to wait for our quotas to free up again.
Under small load, the wait times would likely be minimal, but if it spikes, or if you exceeded a multi-tiered quota, then it's possible for hundreds of functions to spin up and be sitting their waiting for available capacity. You could mitigate this within your code (e.g. re-queuing messages if your per day quota was exceeded), or by using concurrency settings to minimize parallel executions and potential collisions, but that opens up all of the problems we already discussed. Bottomline, these solutions seem brittle to me and would require additional monitoring and tweaking to get them right. This isn't what serverless is all about.
Implementing a better solution
So now that we've looked at a bunch of ways not to do this, let's design an architecture that will meet the following criteria:
- 100% serverless: We do not want to be responsible for additional dependencies
- Cost effective: Our solution should not require over-provisioning of resources to handle peak loads
- Scalable: The system should be able to scale, even if the downstream resources are throttled or become unavailable
- Resilient: If parts of our system fail, whether that's because of a bad message or a downstream outage, we should be able to recover with minimal (if any) human intervention
- Efficient: We want to make sure that we are fully utilizing our available quota units
- Coordinated: The system should be aware of failures, exceeded quotas, and outages to minimize unnecessary invocations.
That sounds easy enough, right? 😉 Let's give it a go.
Here is my proposed solution. I call it the Lambda Orchestrator, but only because I couldn't think of a better name. Take a minute to review the diagram below, and then we'll discuss what's going on here.
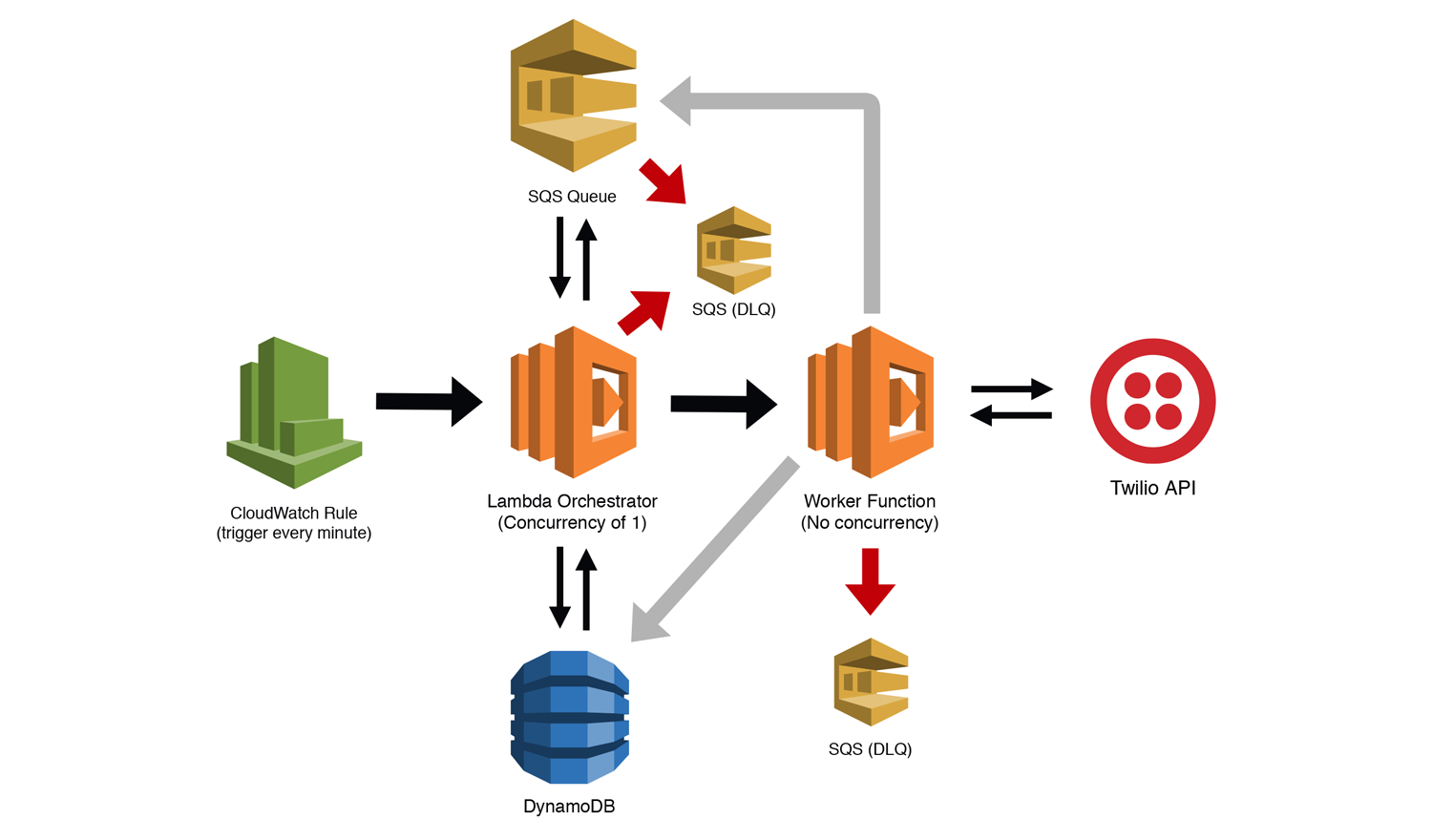
We'll start by looking at each of the components, and then examine how data will flow through the system.
SQS Queue
This will store the jobs that require some call to your third-party API (we're using Twilio here as an example). How you populate this queue is completely up to you. We are attaching a Dead Letter Queue (DLQ) as part of this queue's redrive policy. If our Lambda function that is polling this queue errors multiple times (up to you how many), we'll move the bad messages to a DLQ to be examined later.
Lambda Orchestrator Function
Here we create a Lambda function with a concurrency of 1. This function will act as our orchestrator, allowing us to fan out both concurrent and serial tasks, depending on the restrictions of our downstream API. We are also giving this function permission to move messages to our DLQ. This let's us detect bad messages and move them ourselves instead of failing the message multiple times and letting the SQS redrive policy handle it. We want this function to help us maintain state (at least for a little while) so we will set the timeout to something like 5 minutes. We would also likely set the memory of this function to something low. We are not doing heavy lifting with this, so we can keep our costs down this way.
DynamoDB Table
Our DynamoDB table will store a few fields that will help coordinate executions, manage quotas, and help us deal with outages using the circuit breaker pattern. More on this in a minute.
Worker Lambda Function
This function calls the API, performs whatever business logic/processing needs to be done, and then triggers whatever process needs to happen afterwards. NOTE: I did not picture this in the diagram as it is outside the scope of this pattern. The Worker Function also has a separate DLQ attached. Because we are invoking this function from our Orchestrator Function asynchronously, it's possible that we could lose events if the function fails. By adding the DLQ, we will be sure to capture failed events, allowing us to examine them later.
CloudWatch Rule
The CloudWatch Rule triggers our Orchestrator Function every minute to start the processing as well as to restart the function if there were any catastrophic failures. Our Orchestrator Function has a concurrency of 1, so if the function is already running, the CloudWatch Rule will be throttled.
The Third-Party API
This is the API we'll be calling (Twilio in this example). Note that this is likely a synchronous call, meaning our Lambda function will be waiting for a response before it can continue processing. The amount of time this takes to process should be of no concern to our quota limits. If the API allows 1 call per second, but each call takes 3 seconds to respond, our system will still send a new call every second.
Implementation details and data flow
Now that we have identified the components, let's look at how data flows through the system.
1. CloudWatch Rule triggers the Lambda Orchestrator
If the orchestrator is already running, the call will be throttled. We want this to happen because we only need a single instance of the orchestrator running at once.
2. The Lambda Orchestrator queries DynamoDB
The first step is to hydrate the Lambda function with our saved state. We need to ensure that multi-tiered quotas (per day, per month, etc.) haven't been exceeded and that the circuit hasn't been opened because of a recent API call failure. If the case of exceeded quotas, you might want to send an alert notifying someone that these limits have been reached. We'll deal with open circuits in the next step.
3. The Lambda Orchestrator polls the SQS Queue
If our quotas haven't been exceeded, we can go ahead and poll our SQS queue so that we can start processing messages. Assuming our circuit is closed (meaning there have been no recent failures calling the API), then we would likely retrieve a batch of messages (10 is the max). We can then loop through those messages, pausing between them to conform to our quota requirements, and then invoke our Worker Function asynchronously using the AWS SDK. We would use global variables to keep track of our API calls, and then write that information back to DynamoDB after every few iterations. We also want to check the current status of our circuit.
If our circuit is open, we can pause for a few seconds, and then invoke the Worker Function with a special "Health Check" invocation event. We would likely pause for another period of time, query DynamoDB again to see if the circuit was still open, and then repeat the process.
4. The Worker Function(s) do their job
When the Worker Function is invoked with a regular message, it calls the remote API, waits for the response, and then does whatever post processing it needs to do. This could be adding a message to another queue, sending a message with SNS, adding something to a Kinesis stream, writing to a database, etc. NOTE: The post-processing step is not included in the diagram above.
If the above all went to plan, then the worker is finished and can terminate gracefully. However, if the API call fails, we need to deal with it and let the system know that the API isn't responding correctly. The first step is to make a call to DynamoDB and flag the circuit as "OPEN." Remember that in the previous step, we are periodically checking the circuit's status, which will tell the system to stop invoking the worker. This will reduce future failures, but what about the messages already in flight? No problem. We can re-queue these messages from our worker and put them back in the main queue.
If the circuit is open, the previous step will invoke our worker with a "Health Check" event. This will tell the system to call the remote API with some sort of "status" request (see your API's documentation) to test if it is responding. If not, we do nothing and wait for the next health check. If it does respond correctly, we make a call to DynamoDB and flag the circuit as "CLOSED." Regular traffic should start flowing again.
Final Thoughts
Using this pattern, you can achieve incredibly high levels of throughput even during peak load times that might otherwise cause you to exceed your downstream API quotas. We've also accounted for execution failures, downstream errors, and complete service outages. By using a long-running (likely low memory) Lambda function as our orchestrator, and DynamoDB with low capacity as our state manager, we can run our own serverless state machine for something ridiculously cheap, like less than $2 per month. And that's if it is running 24/7.
We could also use this pattern to (almost) guarantee order. If we used a FIFO SQS queue instead of a standard one, we could invoke our API calls in a highly-ordered fashion. I say "almost guaranteed ordering" because if the third-party API went down and we had to re-queue messages, then they would be put at the end of the queue. However, you could have a "re-queued" queue that was checked first by your orchestrator.
Are there other ways to do this? Of course there are. We could have used Kinesis instead of SQS, for example, and I'm sure you can think of other possible patterns as well. Hopefully this gave you some ideas to help make your serverless applications more reliable and resilient.
If you found this useful and you'd like to see a sample project that uses it, let me know in the comments.