Takeaways from AWS re:Invent 2019's Amazon DynamoDB Deep Dive: Advanced Design Patterns (DAT403)
Rick Houlihan delivered another mind-bending edition of his Advanced Design Patterns for DynamoDB talk at re:Invent this year. Here are my 12 key takeaways.

AWS re:Invent 2019 is a wrap, but now the real work begins! There are hundreds of session videos now available on YouTube. So when you have a few days (or weeks) of downtime, you can dig in to these amazing talks and learn about whatever AWS topics you fancy.
I was only able to attend a few talks this year, but one that I knew I couldn't miss in person, was Rick Houlihan's DAT403: Amazon DynamoDB deep dive: Advanced design patterns. At the last two re:Invents, he gave similar talks that explored how to use single-table designs in DynamoDB... and they blew my mind! 🤯 These videos were so mind-bending, that they inspired me to immerse myself in NoSQL design and write my How to switch from RDBMS to DynamoDB in 20 easy steps post. I was hoping to have a similar experience with this year's edition, and I WAS NOT DISAPPOINTED.
As expected, it was a 60 minute firehose of #NoSQL knowledge bombs. There was A LOT to take away from this, so after the session, I wrote a Twitter thread that included some really interesting lessons that stuck out to me. The video has been posted, so definitely watch it (maybe like 10 times 🤷♂️), and use it to get started (or continue on) your DynamoDB journey.
Here is the video, as well as my 12 key takeaways from the talk. Enjoy!
12 Key Takeaways
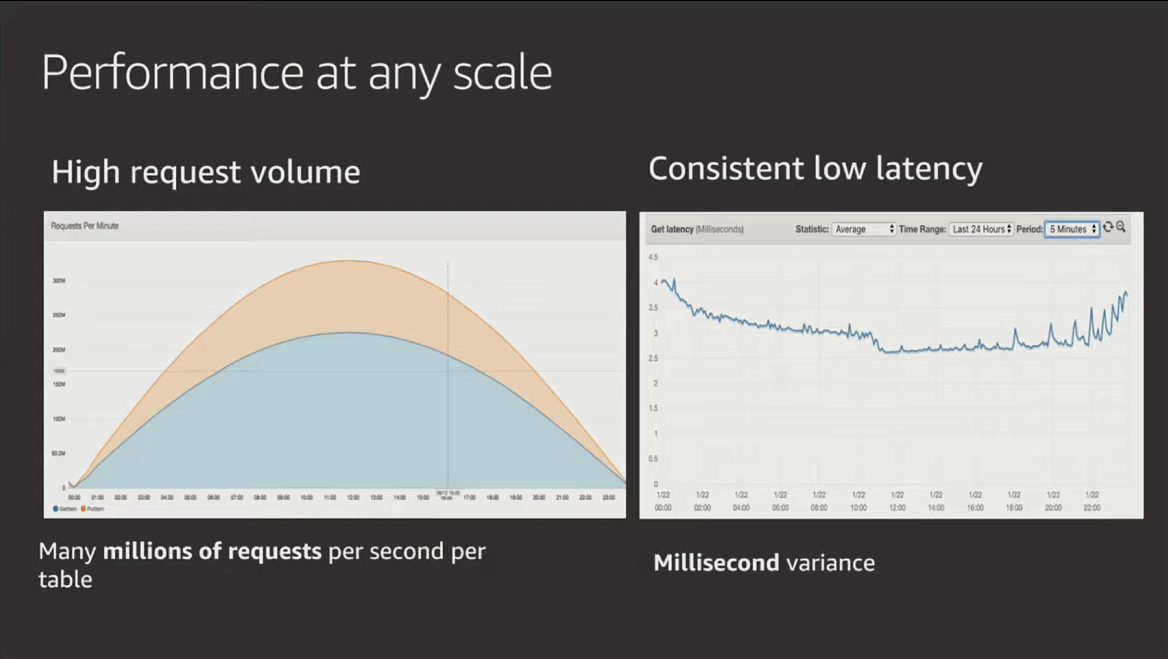
1. DynamoDB performance gets BETTER with scale
Yup, you read that correctly, the busier it gets, the faster it gets. This is because, eventually, every event router in the fleet caches your information and doesn't need to look up where your storage nodes are. 🚀
2. Big documents are a bad idea!
It's better to split data into multiple items that (if possible) are less than 1 WCU. This will be a lot cheaper and cost you less to read and write items. You can join the data with a single query on the partition key.
Rick clarified this statement for me on Twitter by adding, "I prefer to say keep items as small as possible by structuring to contain only data that is relevant when they are accessed, e.g. don't store immutable data in the same item as data that changes frequently. Use two items sharing a PK and write to one, query the PK to read both."

3. You don't want to denormalize highly mutable data
Data that is likely to change often should probably be referenced, which can then be retrieved with a separate query (when necessary). Immutable data (like DOB, name, email, etc.) can be denormalized for optimizing data shapes.
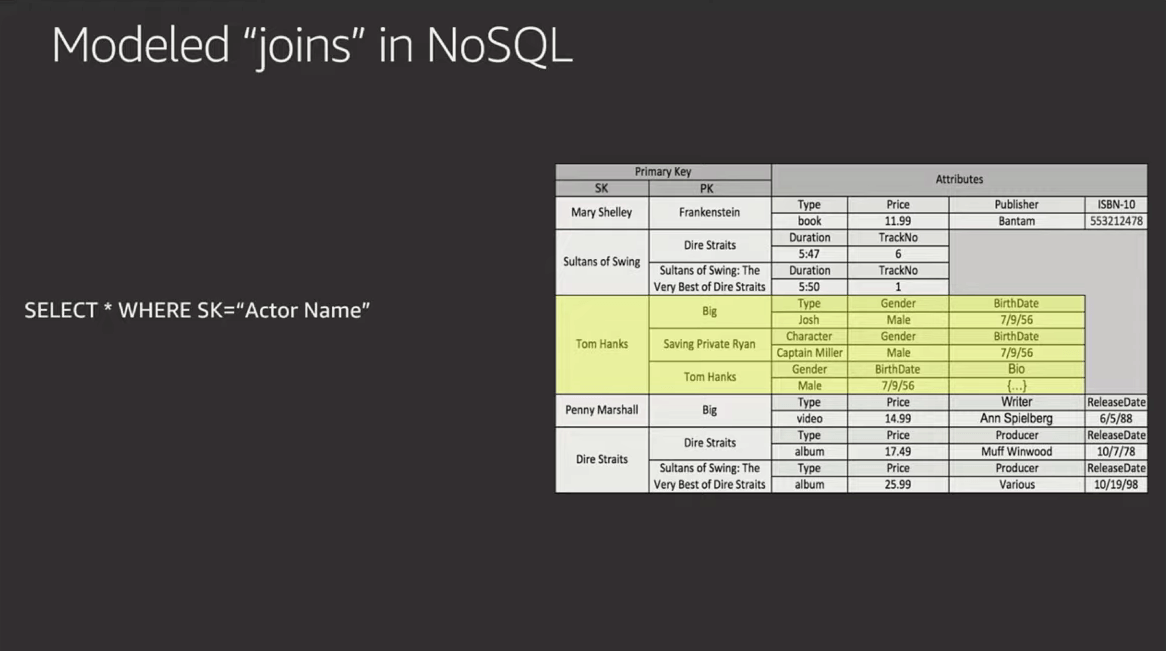
4. Don't use auto-generated primary keys as partitionKeys if they are not used by your primary access pattern
If your application doesn't use those ids directly (meaning you're using them just as a reference id), then you are creating a "dead index." This will require the creation of additional GSIs just to index meaningful references (like email or username). Forget third-normal form and other relational patterns.
5. Avoid running aggregation queries, because they don't scale
Use DynamoDB streams to process data and write aggregations back to your DynamoDB table and/or other services that are better at handling those types of access patterns. Lambda functions make great decoupled, asynchronous stored procedures that can process data changes without affecting database performance.
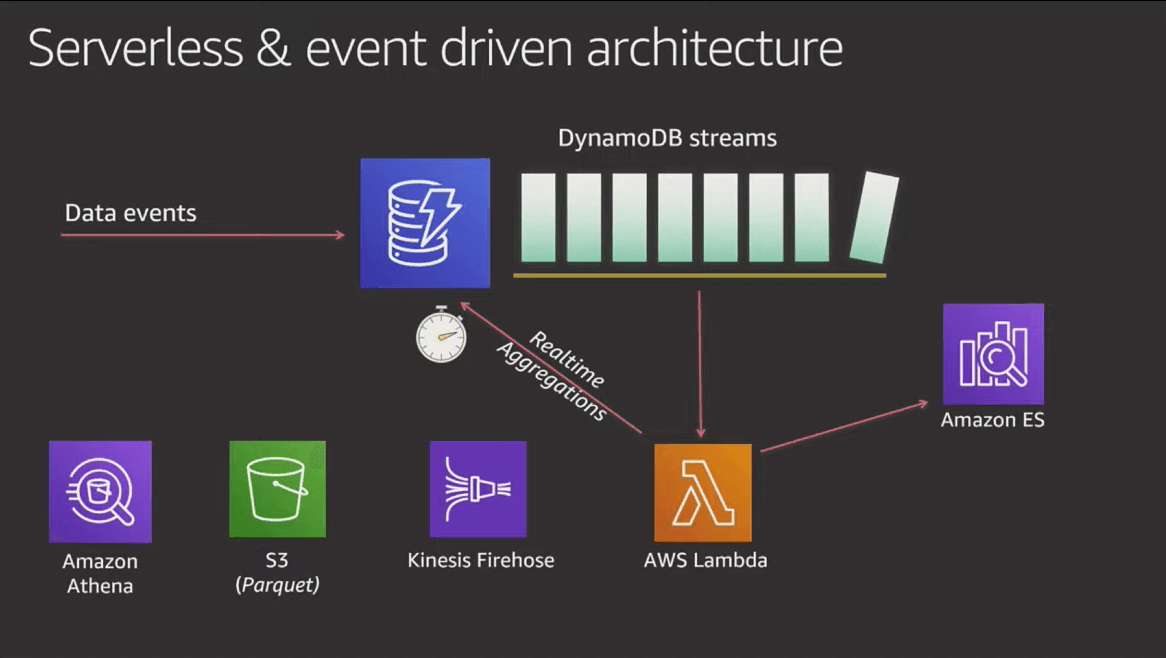
6. Build idempotency into your DynamoDB stream processors
DynamoDB streams guarantee "at-least-once" delivery, which means your Lambda could receive the same event twice. Plan for that by building idempotency into your Lambda functions or downstream services.
7. When you need to add a new access pattern, "You don't necessarily have to remodel everything and throw the baby out with the bathwater."
This was the first time I've ever heard Rick say that there could be some flexibility with your NoSQL single-table designs. If you need to add a new access pattern, or change an existing one, Rick suggested that you run an ETL task to decorate existing items or change some values. Maybe add a new GSI if necessary.
8. When possible, push certain logic down to the client
Rather than filtering out old versions or calculating availability by diff'ing existing items, let the client do that math instead of your application layer. #RickProTip
9. Use write sharding to store large indexes with low cardinality
Rick gave the example of languishing support tickets. Write these to multiple partitions on a GSI (using some hashing) and then use a once-a-day look up to decorate other items. Parallelization is an added benefit when you are processing these records.
10. Use an attribute versioning pattern to store deltas for large items with minimal changes between mutations
Don't duplicate a massive item every time some small part changes. Instead, store each attribute as an item with the same partitionKey. This allows you to optimize writes to small records versus having to rewrite the entire document. (see takeaway #2)

11. Use NoSQL Workbench for DynamoDB
You can model your table, add indexes, and pivot your data visualizations. Plus, Rick uses it to model his tables and create the diagrams for his slide decks. Do you really need another reason? Download it here!
12. Your workload most likely fits into a single DynamoDB table 🤓
Rick's latest example shows 23 access patterns using only THREE GSIs. Is it easy? Not really. Can it be done? Yes, and I have faith in you. 😉 #SingleTableForEveryone
Here are the 23 access patterns along with the table schema and GSIs used to build the "Employee Portal" he outlines in the video (starting at 41:31). The slides are below for quick reference, but I suggest you watch him walk through and explain them in the video.
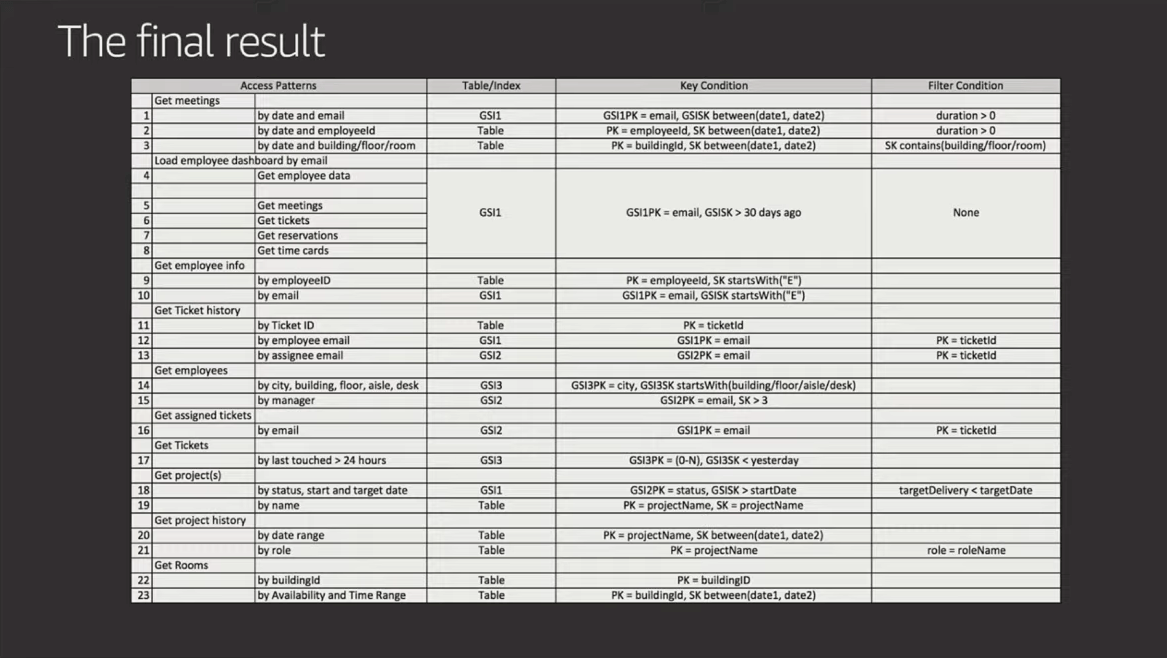
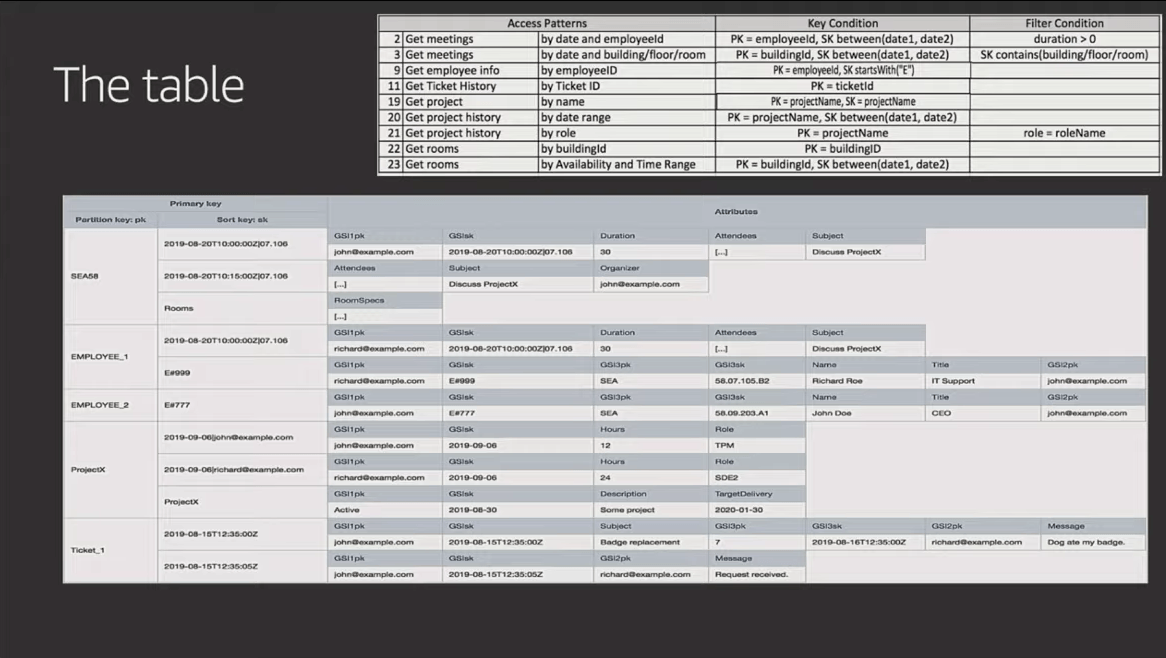
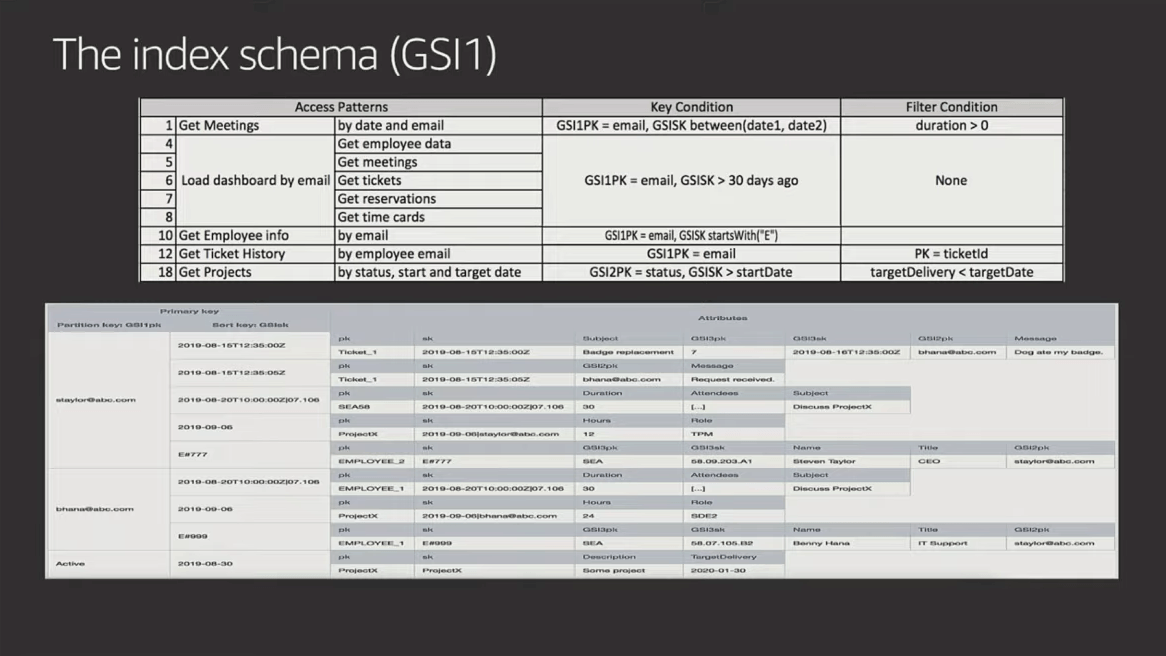
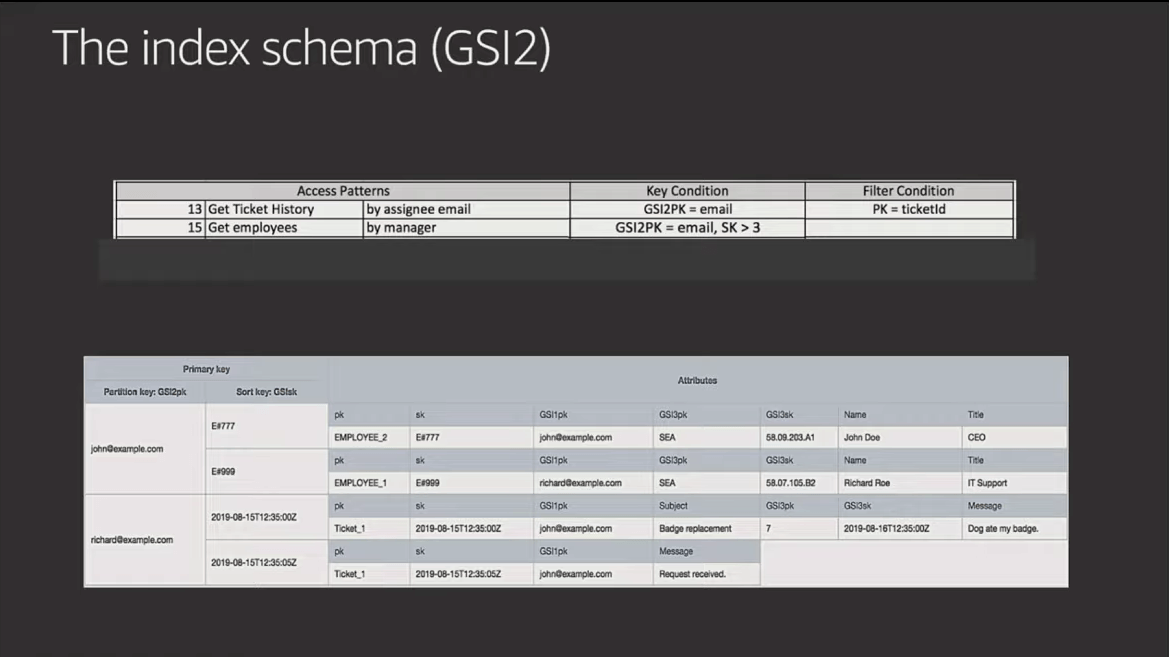
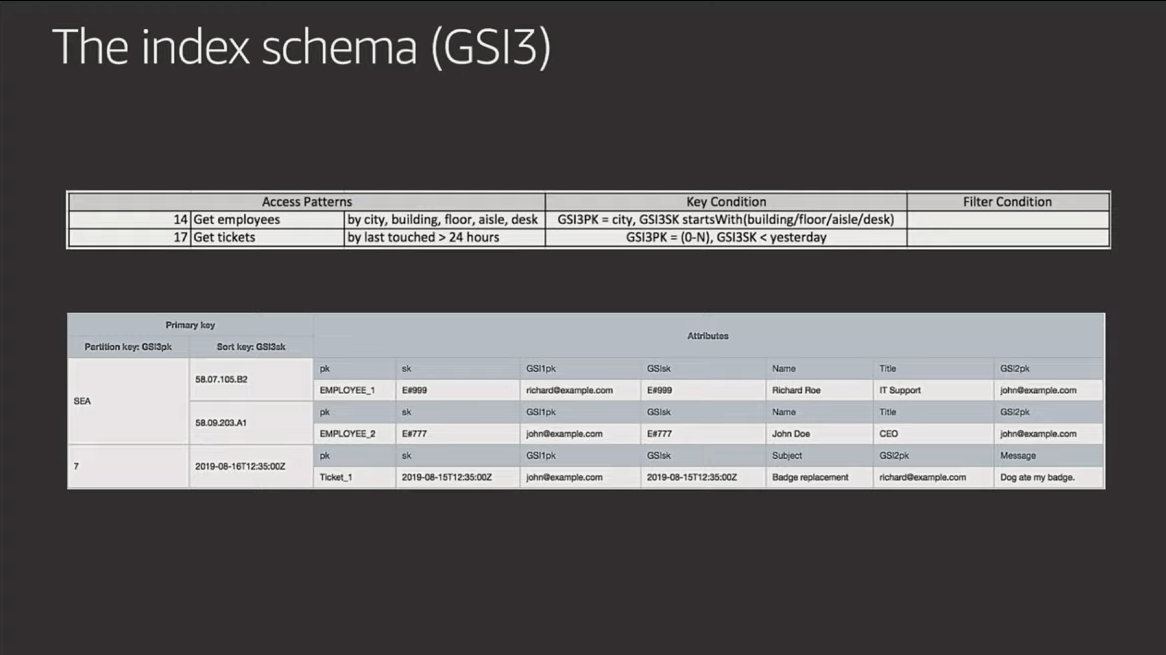
Something to study in the example above is how Rick not only denormalizes data across items, but also duplicates attributes in the SAME ITEM. The storage costs related to these patterns are very low, but this benefits the efficiency and total size of the indexes because it makes use of sparse indexes to minimize what data gets indexed.
Where do we go from here?
The sky's the limit! There were a ton of excellent talks related to DynamoDB at re:Invent, and lucky for us, there is a YouTube Playlist that has them listed for you. One of these talks is from my good friend Alex DeBrie, which you should totally check out. He walks you through a single-table design with just five access patterns, but utilizes different strategies for each. This should give you something very powerful, but with less brain-melting caused by Rick's examples.
You can also check out Build On DynamoDB | S1 E2 – Intro to NoSQL Data Modeling with Amazon DynamoDB and Build with DynamoDB | S1 E3 – NoSQL Data Modeling with Amazon DynamoDB from the teams at AWS. There's a great post by Forrest Brazeal called From relational DB to single DynamoDB table: a step-by-step exploration that walks through an example using the Northwind design from MS Access. Alex DeBrie also has a great resource at DynamoDBGuide.com and he's writing a book about DynamoDB modeling that I'm super excited about.
If you want to get hands on, check out the new DynamoDB Toolbox open source project that I'm working on. It's a simple set of tools for working with Amazon DynamoDB and the DocumentClient. It lets you define your data models (with typings and aliases) and map them to your DynamoDB table. You can then generate parameters to put, get, delete, and update data by passing in a JavaScript object. The DynamoDB Toolbox will map aliases, validate and coerce types, and even write complex UpdateExpressions for you. There's been a lot of great feedback so far, so hopefully this will help you out.
There is a tremendous amount of power that DynamoDB (and single-table designs) gives you. Not just from a scalability standpoint, but also from an efficiency, disaster recovery, and maintenance standpoint. I know it's hard to wrap your head around, but didn't you feel the same way when you first encounter SQL JOINs and third-normal form? NoSQL data modeling is a hugely valuable skill, so if you've got the time (and the stomach) for it, I highly encourage you to learn it.
Please note: All slide images were used with express permission from Rick Houlihan and Amazon Web Services.