Getting abstractions wrong with AWS SAM Serverless Connectors
AWS SAM Serverless Connectors are an attempt to abstract away the IAM complexities of connecting serverless services. Unfortunately, they missed the mark.

I was intrigued when I first saw the announcement of AWS SAM Serverless Connectors. I don't use SAM very much (if at all anymore), so it wasn't the hope of this being some sort of silver bullet for my occasional IAM frustrations that got my attention. Rather, it was another opportunity to learn how AWS is trying to abstract away their mostly self-imposed complexity problems. Unfortunately, I think they missed the mark on this.
Finding the right level of abstraction is hard. Us developers are a finicky bunch, and we know what we like, and like what we know. Providing too high a level of abstraction will turn most of us off, but providing too low of an abstraction could mean introducing new complexity that outweighs the benefits gained. Case in point: [AWS::Serverless::Connector](https://docs.aws.amazon.com/serverless-application-model/latest/developerguide/sam-resource-connector.html). The motivations are pure, and the simplistic idea of a Destination, a list of Permissions, and a Source make total sense. The problem is that the services it connects are much too varied to let this abstraction serve as a universal connector.
Let's start with this basic example from the docs:

So as long as you are in a single SAM template, an Id for the Source and Destination are all you need to enable "Read" and "Write" access to your DynamoDB table. Seems simple enough. Except, as Allan Chua points out, it takes 9 lines of code versus 3 lines using AWS SAM policy templates. Verbosity isn't always a bad thing, especially if it provides clarity that makes reasoning about your IaC easier, but I don't think that applies here.
To be clear, I'm not a huge fan of policy templates either (I'll explain why in a minute), but I do like that they are at least organized within the function configuration. Serverless Connectors can be anywhere within your SAM template. This means that in order to know which services your function has access to, or potentially which services have access to your function, you need to search out a disconnected piece of configuration drivel. This may be trivial in a small template, but Allan's example of just a few integrations start to show the extra bloat. Imagine a template with lots of functions, each with their own sets of connectors?
Beyond the potential added bloat in a single template, there is also a very good chance that your applications will grow to include multiple stacks that need to interact with one another. A single API that spans multiple templates, a shared datastore, or an SQS topic with consumers and producers in separate stacks come to mind.
Take this example from the docs:

We're now specifying a Type, the ResourceId, and in this case, the Qualifier, which is a (slight) shortcut to specifying the ARN and resource. Maybe I'm a bit old fashioned, but I'm not seeing a particular advantage over the IAM policy below, which came up as the first result when I Googled "iam permission for allowing post to lambda from api gateway."
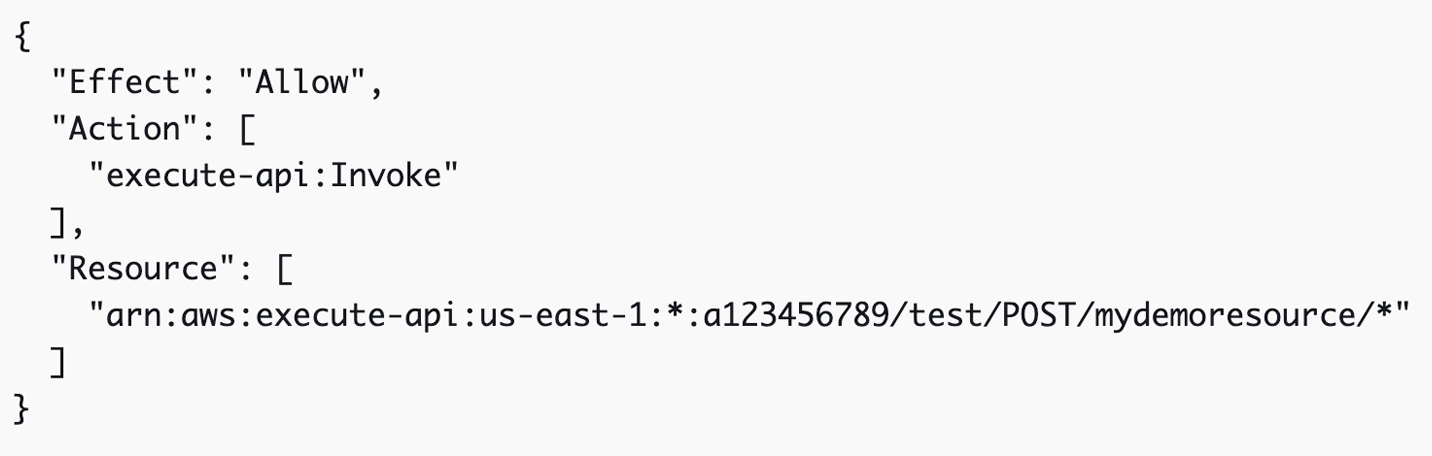
There's another disconnect that becomes a bit obvious here: the Read and Write semantics. While it sort of makes sense (I think) that you are "writing" to a Lambda function on an HTTP POST request, the underlying permission is execute-api:Invoke. Now, I may be wrong here (because I didn't test this), but I'm guessing that either Read or Write permissions would translate to Invoke. So I could write a connector that gave "write" permission on a GET route, and "read" permissions on a POST route, and everything would work just fine. Those semantics are wrong, and for the uninitiated, I could see this causing more confusion than it's worth.
Another issue with the Read/Write semantics is their varied scope. Read permission on a DynamoDB table assumes you can do no destructive action, while Write assumes the ability to add and (probably) update data. But Write in this context also gives you the ability to delete items. And what about with an SQS Queue? The Read permission would presumably give you sqs:ReceiveMessage, but that only gets you part of the way there. You also need sqs:DeleteMessage if you want to remove a message from a queue. This would require you to add Write permissions, which would then give you sqs:SendMessage as well. This is not what I want if I have separate consumers and producers. It might just be me, but this doesn't seem intuitive.
Let's go back to DynamoDB for a second. I wrote a post a while ago about Ensuring Data Integrity with DynamoDB. There are a lot of nuances in there that describe situations where you might want to limit upserts, prevent deletes, or isolate attributes. Those might be slightly advanced, but even adding Delete as an option to the Permissions config would add a bit more control and maybe help with the confusing semantics. This is also the primary reason why I don't particularly like SAM Policy Templates. They're too broad, and IMO, discourage the principle of least privilege. But, hey, at least you can see what permissions each one grants.
Like I said, abstractions are hard, and sometimes you just need to go for it and see where it lands. Overall, I think the SAM team does a good job trying to accommodate their users by giving them features that makes building serverless applications easier. But in this case, I think they may have done the opposite.