Aurora Serverless v2: The Good, the Better, and the Possibly Amazing
Aurora Serverless v2 Preview is here, and it looks very promising. I share my initial thoughts and results of some experiments I ran on this major upgrade.

Three years ago at re:Invent 2017, AWS announced the original Amazon Aurora Serverless preview. I spent quite a bit of time with it, and when it went GA 9 months later, I published my thoughts in a post titled Aurora Serverless: The Good, the Bad and the Scalable.
If you read the post, you'll see that I was excited and optimistic, even though there were a lot of missing features. And after several months of more experiments, I finally moved some production workloads onto it, and had quite a bit of success. Over the last 18 months, we've seen some improvements to the product (including support for PostgreSQL and the Data API), but there were still loads of problems with the scale up/down speeds, failover time, and lack of Aurora provisioned cluster features.
That all changed with the introduction of Amazon Aurora Serverless v2. I finally got access to the preview and spent a few hours trying to break it. My first impression? This thing might just be a silver bullet!
I know that's a bold statement. 😉 But even though I've only been using it for a few hours, I've also read through the (minimal) docs, reviewed the pricing, and talked to one of the PMs to understand it the best I could. There clearly must be some caveats, but from what I've seen, Aurora Serverless v2 is very, very promising. Let's take a closer look!
Update December 9, 2020: I've updated the post with some more information after having watched the "Amazon Aurora Serverless v2: Instant scaling for demanding workloads" presentation by Murali Brahmadesam (Director of Engineering, Aurora Databases and Storage) and Chayan Biswas (Principle Product Manager, Amazon Aurora). The new images are courtesy of their presentation.
What's Aurora Serverless again?
For those that need a refresher, "Amazon Aurora Serverless is an on-demand, auto-scaling configuration for Amazon Aurora. It automatically starts up, shuts down, and scales capacity up or down based on your application's needs. It enables you to run your database in the cloud without managing any database capacity." Sounds amazing, huh?
Aurora Serverless separates the data and compute layers so that each one can be scaled independently. It uses distributed, fault-tolerant, self-healing storage with 6-way replication that will automatically grow as you add more data. The data is replicated across multiple availability zones within a single region, which helps provide high availability in the event of an AZ failure.
Aurora Serverless v1 uses a pool of warm instances to provision compute based on your ACU (Aurora Compute Unit) needs. These pre-provisioned instances attach to your data and behave similar to a typical provisioned database server. However, if certain thresholds are crossed (max connections and CPU), Aurora Serverless v1 will automatically move your data to a larger instance and then redirect your traffic with zero downtime. It will continue to scale up as needed, doubling capacity each time. Once traffic begins to slow down, your data will be moved to smaller instances.
Instances run in a single availability zone. In the event of an AZ failure, a new instance will automatically be provisioned in another AZ, your data will be attached, and your requests will begin routing again. Based on availability, it could take several minutes to restore access to the database.
There are also a lot of things that Aurora Serverless v1 can't do. Most notably: global databases, IAM authentication, backtracking, S3 import/export, and Lambda triggers.
So what's so great about Aurora Serverless v2?
I'm glad you asked! A big change for Aurora Serverless v2 has to do with the way the compute is provisioned. Instead of needing to attach your data to differently sized instances, Aurora Serverless v2 instances auto-scale in milliseconds based on application load. Yes, you read that correctly. Using some combination of elastic computing and dark magic, your ACUs will scale instantaneously to handle whatever you throw at it.
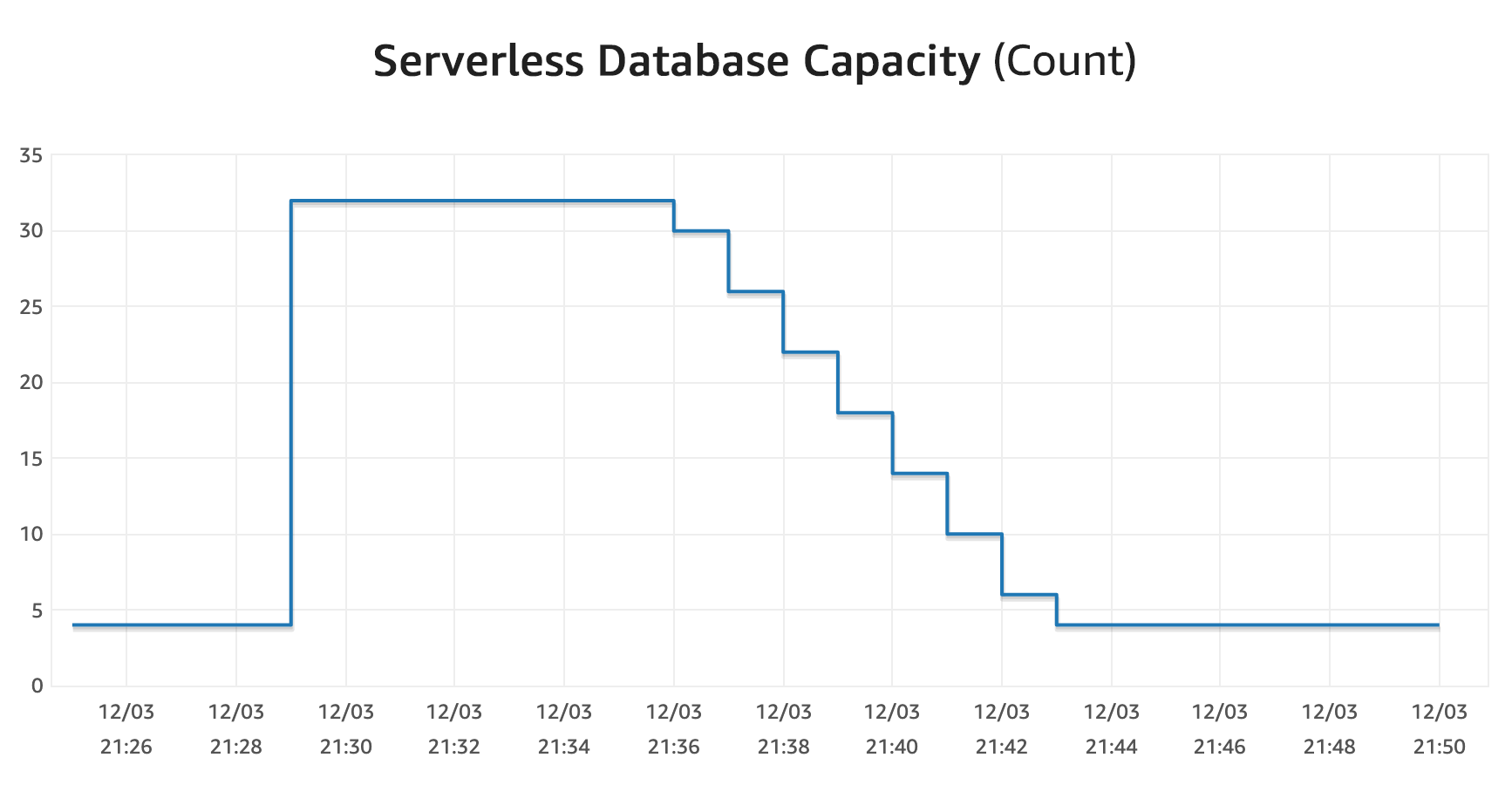
Also, because the instance scaling is elastic, Aurora Serverless v2 increases ACUs in increments of 0.5. This means that if you need 18 ACUs, you get 18 ACUs. With Aurora Serverless v1, your ACUs would need to double to 32 in order to support that workload. Not only that, but the scale down latency is significantly faster (up to 15x). I'll show you some of my experiments later on, and you'll see that scale downs happen in less than a minute.
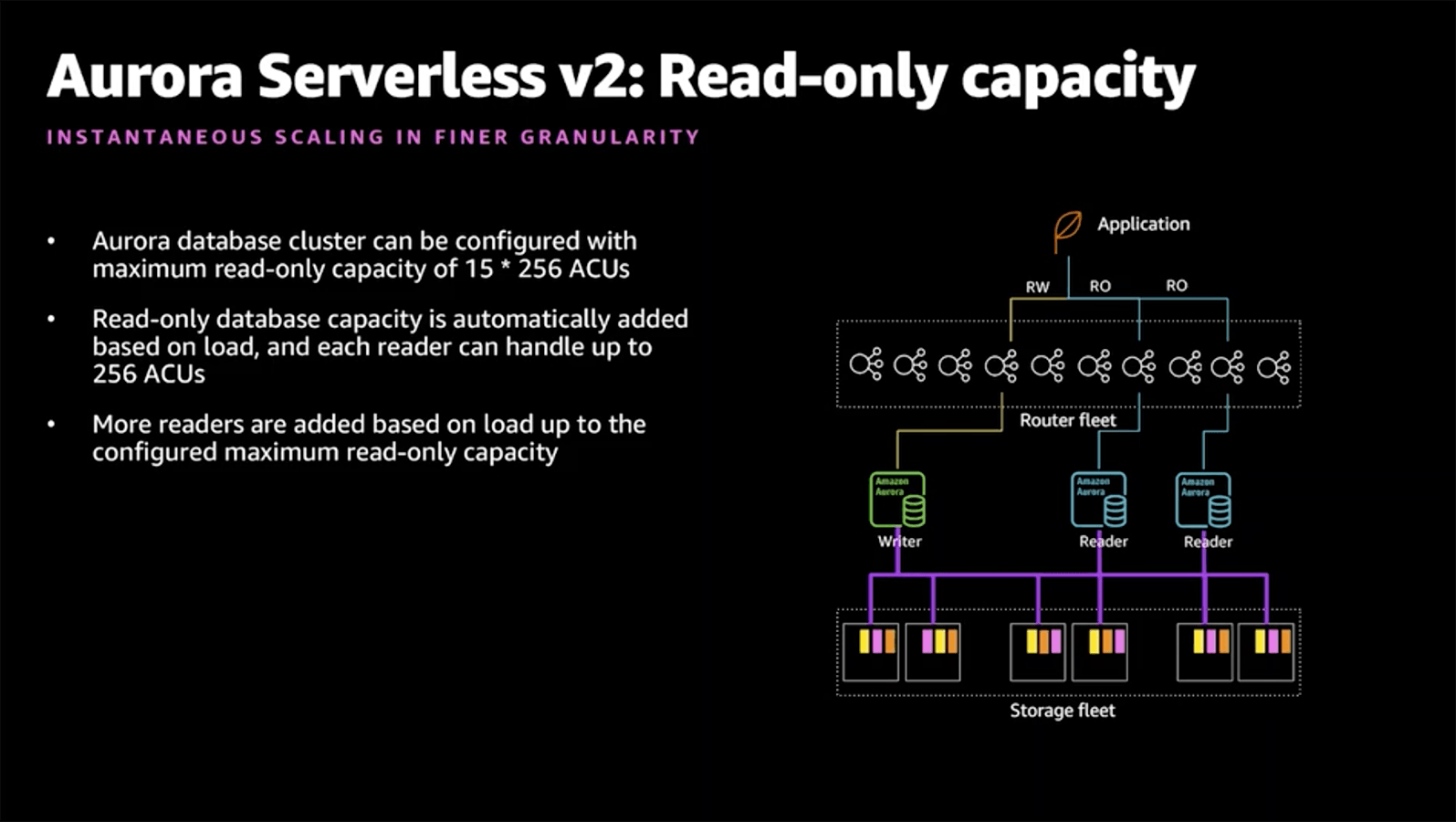
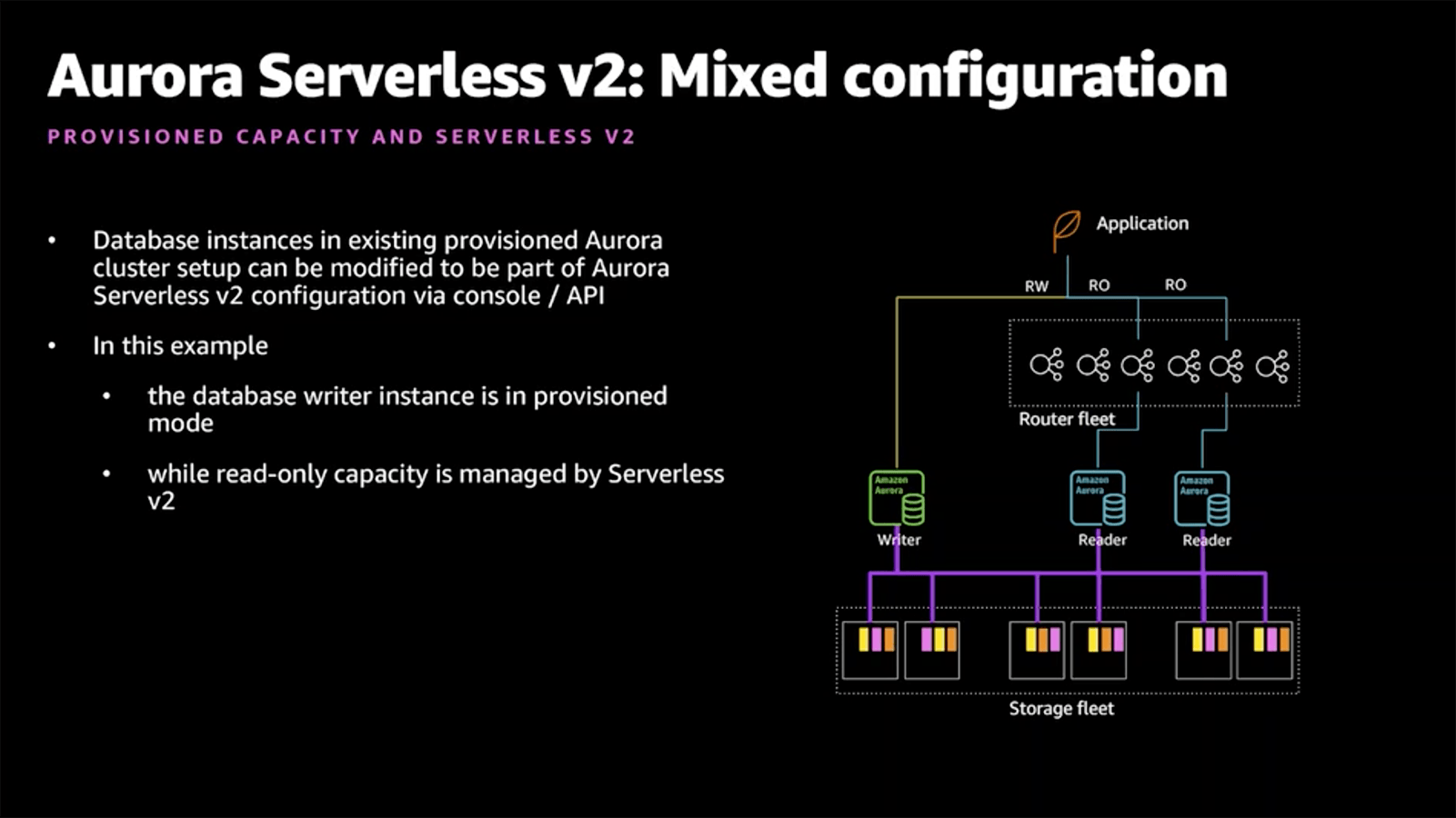
Beyond the amazing scaling capabilities is the fact that "it supports the full breadth of Aurora features, including Global Database, Multi-AZ deployments, and read replicas." This seems pretty darn clear that Aurora Serverless v2 intends to support all the amazing Aurora features, including the ones missing from Aurora Serverless v1.
Update December 9, 2020: The re:Invent presentation offered some more insights into the "dark magic" that powers the auto-scaling. There is a "Router fleet" in front of your instances that hold the connections from the application, allowing the capacity to scale without losing client connections.
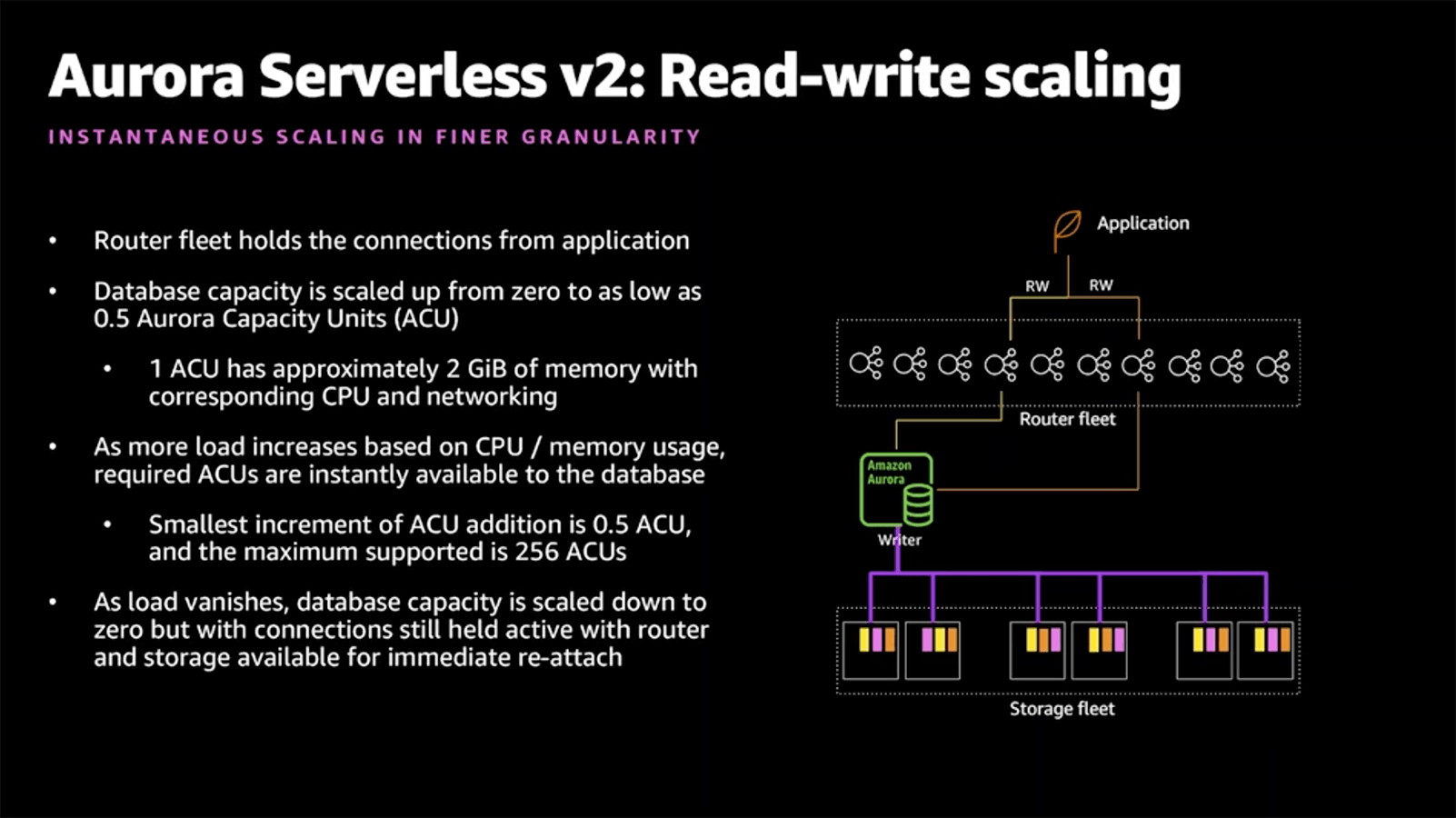
Let's talk about price
There's no way to sugar coat this. The cost of Aurora Serverless v2 seems very high. In fact, v2 ACUs are twice the price of the original v1 ACUs ($0.12 per ACU Hour versus $0.06 per ACU Hour). There is some clever marketing language on the Aurora Serverless page that claims "you can save up to 90% of your database cost compared to the cost of provisioning capacity for peak load." That may be true, but let's break it down a bit.
When they say "provisioned capacity", they mean always on, as in an Aurora provisioned cluster. But before we get into that comparison, let's look at how it compares to Aurora Serverless v1.
So, yes, the price per ACU is double. However, there are some important distinctions here when it comes to how these costs get calculated. One difference has to do with the incremental ACUs of v2 versus the doubling of instance sizes required for v1. I'd like to be able to say that there's an argument that if my workload only needs 9 ACUs, then it would be cheaper than needing to pay for 16 ACUs with v1. Unfortunately, those 9 ACUs would cost your $1.08/hour versus $0.96/hour for 16 v1 ACUs. And if you needed 15 ACUs, well, I think you get the point.
The other difference has to do with the scale down time. This argument might be a little stronger. It can take a while for Aurora Serverless v1 to scale down, like up to 15 minutes according to the documentation. My past experiments showed that this was more like 2-3 minutes, but that was in a controlled environment setting the capacity manually. So even if it took some amount of time in between, it's very likely that you would be paying for a lot of extra ACUs (remember that they get billed by the second). This, of course, only really matters if you have very spiky workloads. Anything more consistent, and things start to get expensive really quickly.
Which brings us back to the "provisioned capacity" comparison. Let's say you were running a db.r5.4xlarge for $2.32/hour. That will run you $1,094.40/month per instance. You know you need some redundancy, so even if you only had a single read replica, that'll cost you another $1,094.40/month for somewhere around $2,188.80/month. With Aurora Serverless v2, we only really need to provision the one cluster (there are some caveats here), so we'd need roughly 64 ACUs to match the peak capacity of the db.r5.4xlarge cluster. If we ran 100% at peak capacity, then that would cost something silly like $5,529.60/month. 😳
But let's get serious. You're not very likely to run at peak capacity. Let's say you have two major spikes per day, low traffic overnight, and fairly minimal traffic during normal hours. For the sake of argument, we'll say 3 hours at peak (95% capacity), 9 hours of normal traffic (40% capacity), and 12 hours of slow traffic (10% capacity). Using our 64 ACU example, that would be (3 * 64 * 0.95 + 9 * 64 * 0.4 + 12 * 64 * 0.1) * $0.12 * 30 = $1,762.56/month. It's not a 90% savings, but compared to peak-provisioning, it still might make a lot of financial sense.
I don't know exactly how they calculate the 90% savings, but if you factor in the amount of over, over-provisioning that goes on, especially if you include multi-tenant workloads, there definitely are some major cost savings possible here. If you're running a fairly steady workload, then you have some calculations to do.
In regards to multi-region replication, Aurora Serverless v2 says it will support Global Database for "sub-second data access in any region and cross-region disaster recovery." I asked for clarification on pricing, and it seems as though you could run a DR cluster in another region with just 0.5 ACUs until you needed it. Or, if you wanted multi-region access, your clusters would just scale with regional demand, which is also pretty cool. As always, data transfer fees apply. 😐
Let's look at some experiments
Since the initial preview of Aurora Serverless v2 is only meant to showcase the scaling characteristics, I spent the majority of my time writing scripts that tried to overwhelm it. Since it's in a test account, I only have the default reserved concurrency of 1,000 on my Lambda functions. I tried a number of different select and insert operations, adding some random delays in long-running Lambda functions to force scaling operations. Granted, these weren't massive numbers, but Aurora Serverless v2 essentially just laughed at me and effortlessly processed my queries.
As an example, I ran 1,000 concurrent session that averaged just over 17,000 queries per second split between SELECTS and INSERTS. There are three separate tests run in the charts below:
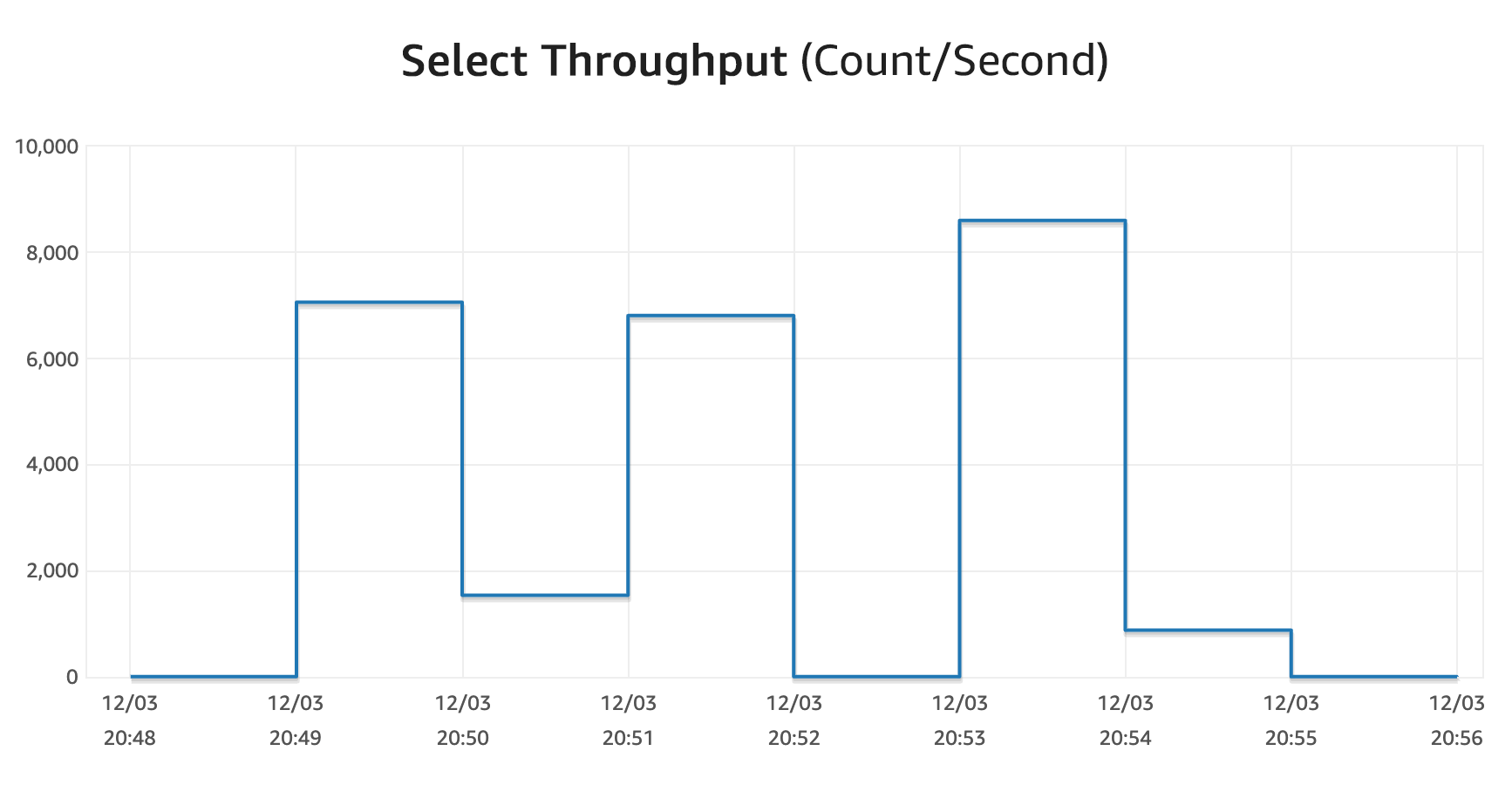
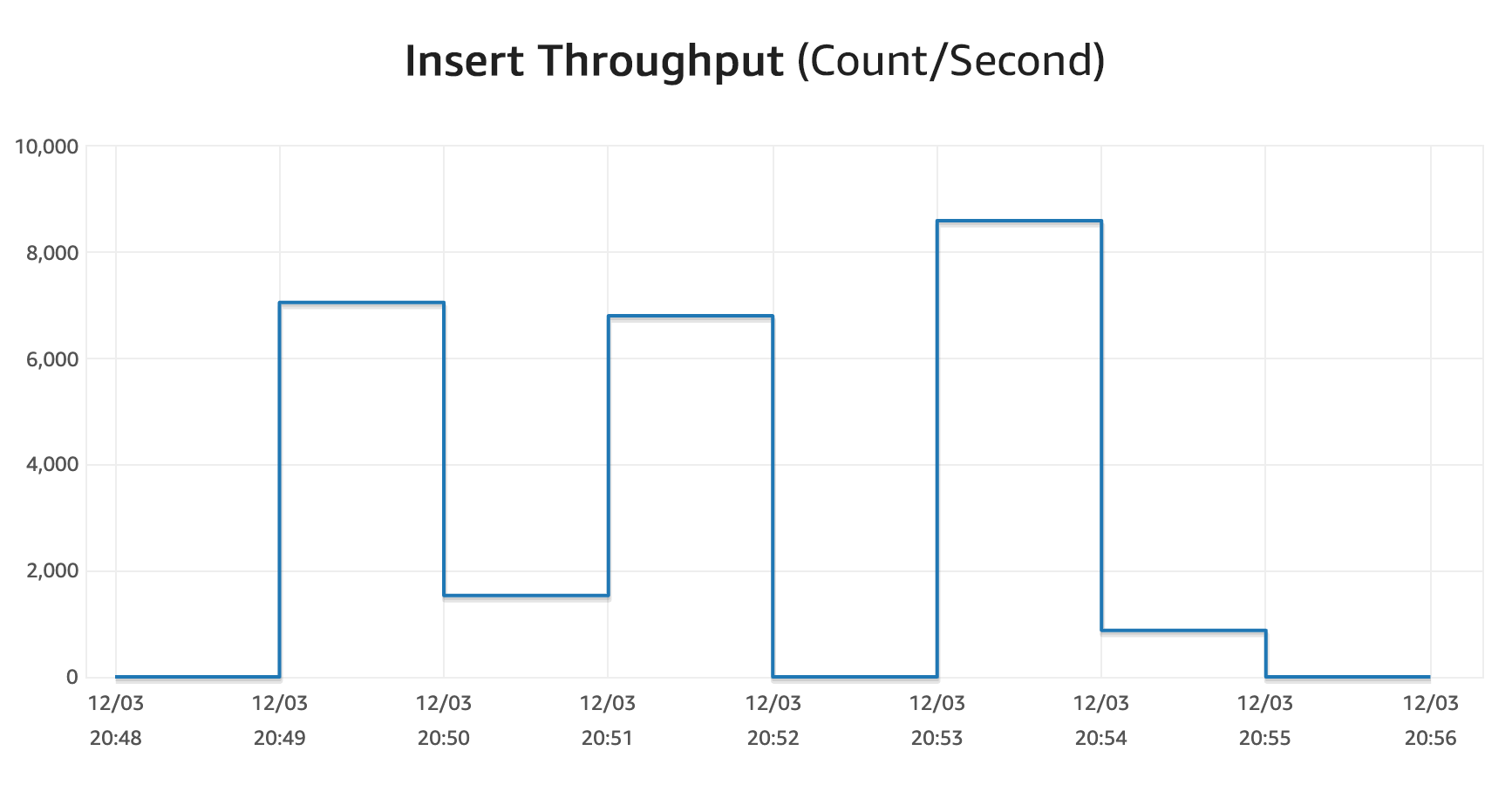
The database capacity (max values) just jumped around to handle the queries with ease, and I never got any errors. The long tail scale down here was mostly due to Lambda functions not closing the connections immediately.
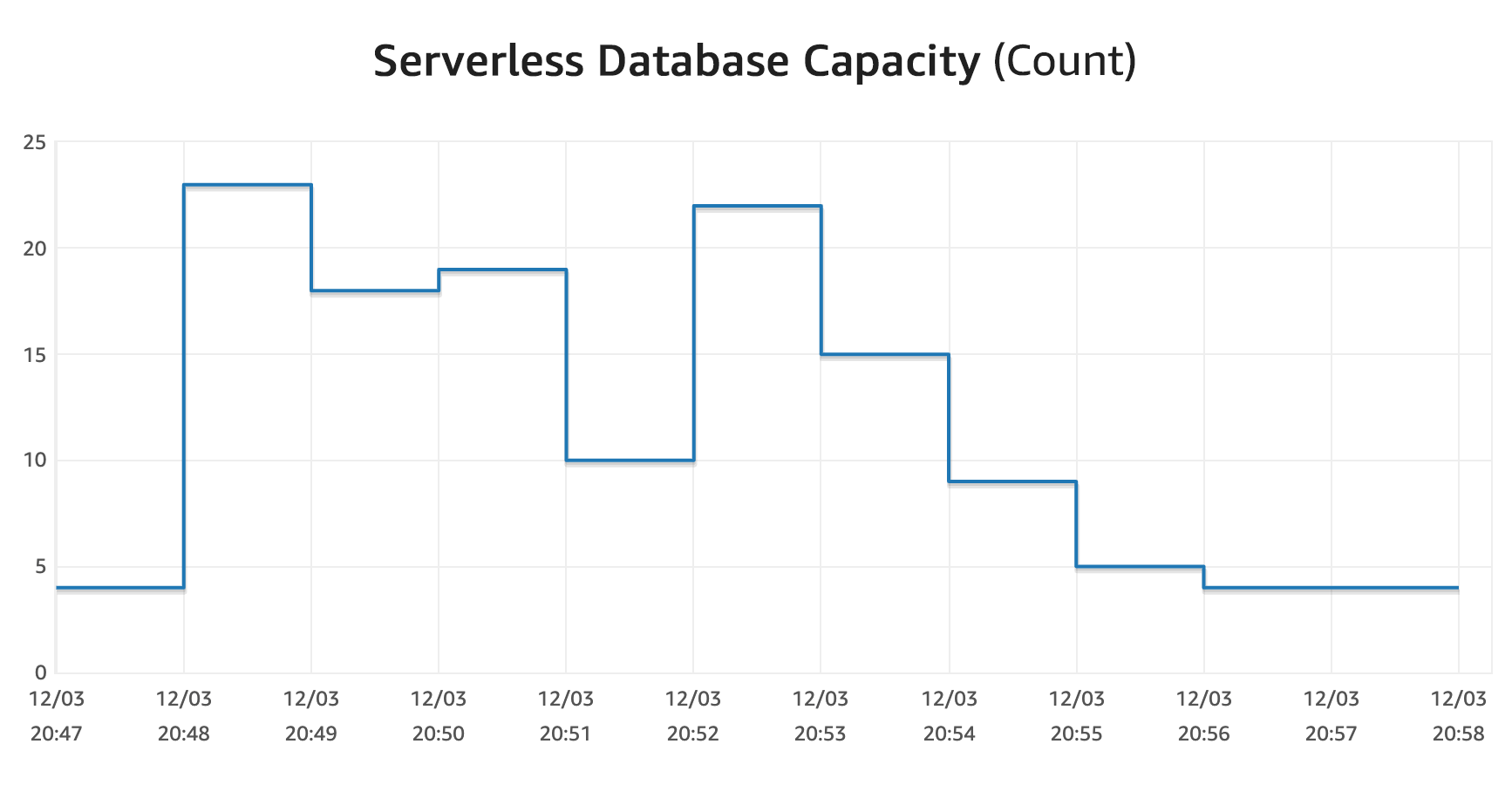
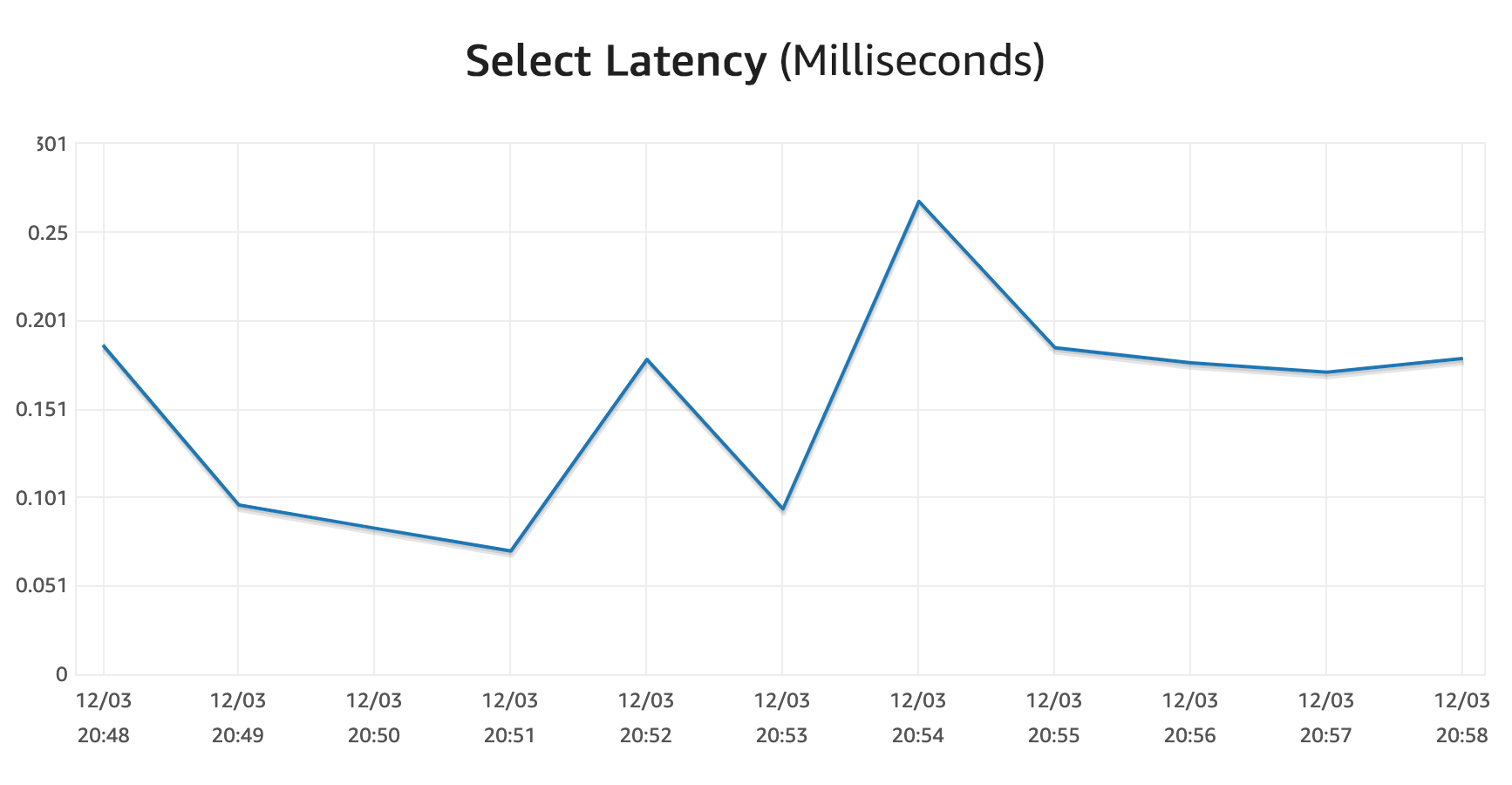
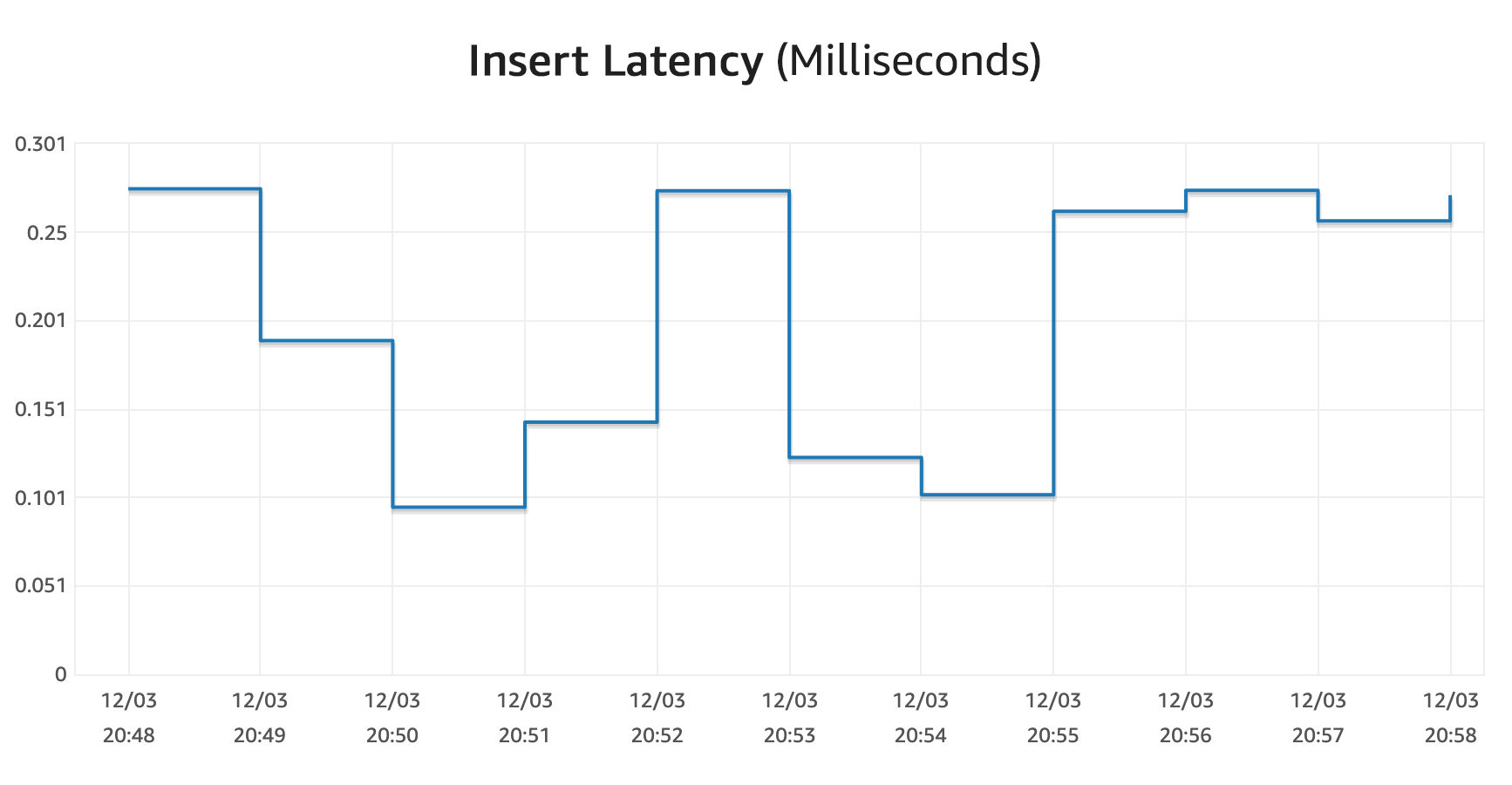
For good measure, I also manually scaled the database up to 32 ACUs (the max that the preview will allow), and the total scale down took about 8 minutes. However, this was controlled by setting the minimum ACUs in the console, so it might work a bit differently when reacting to load changes. I noticed several immediate drop offs during my tests, so in practice, I think it works faster.
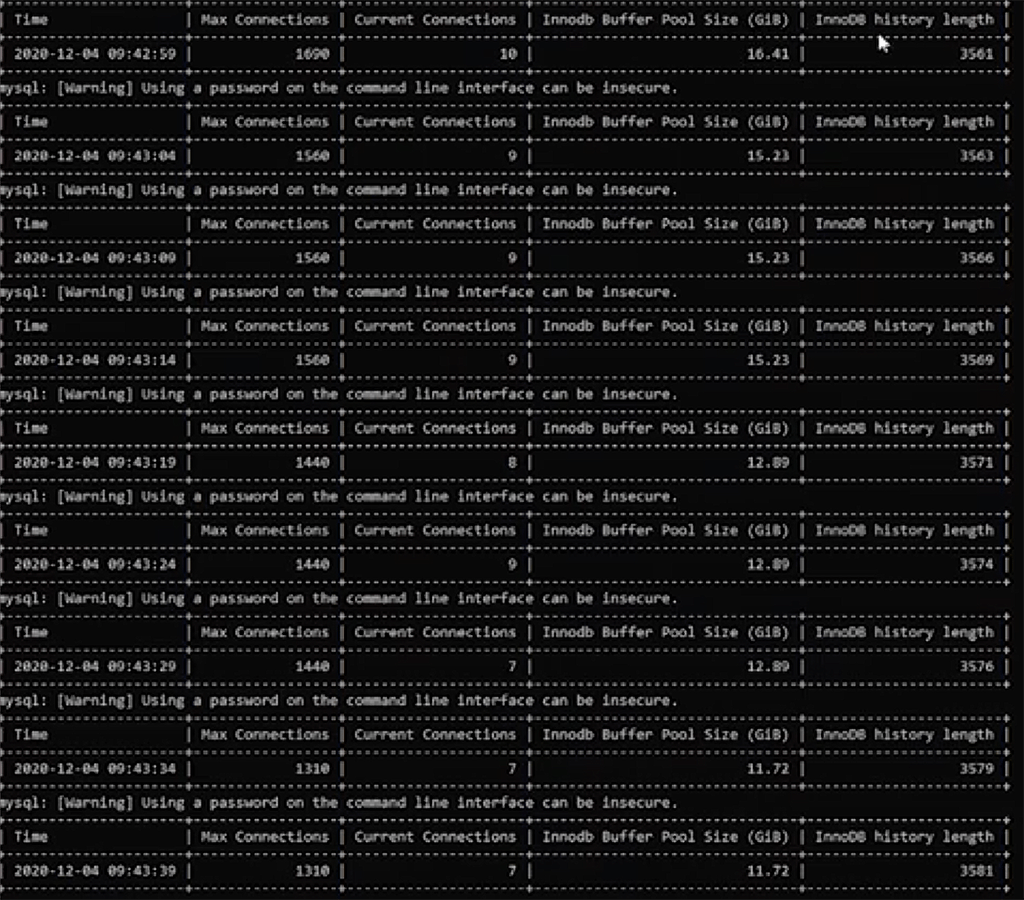
max_connections available at the different ACUs. The minimum ACU setting in the preview was 4, so I couldn't see anything lower than that. Surprisingly, there were only 150 connections available, which is much lower than the 270 available with 4 ACUs in v1. I bumped it all the way up to 32 ACUs and saw 3060 connections available, so a little more than the 3,000 available in v1. I was going to check the others, but I have a feeling they are still tweaking these settings. It might be possible that the lower connection limits have something to do with optimizing the scaling, but I'm just guessing here. Hopefully that will change as the product matures.
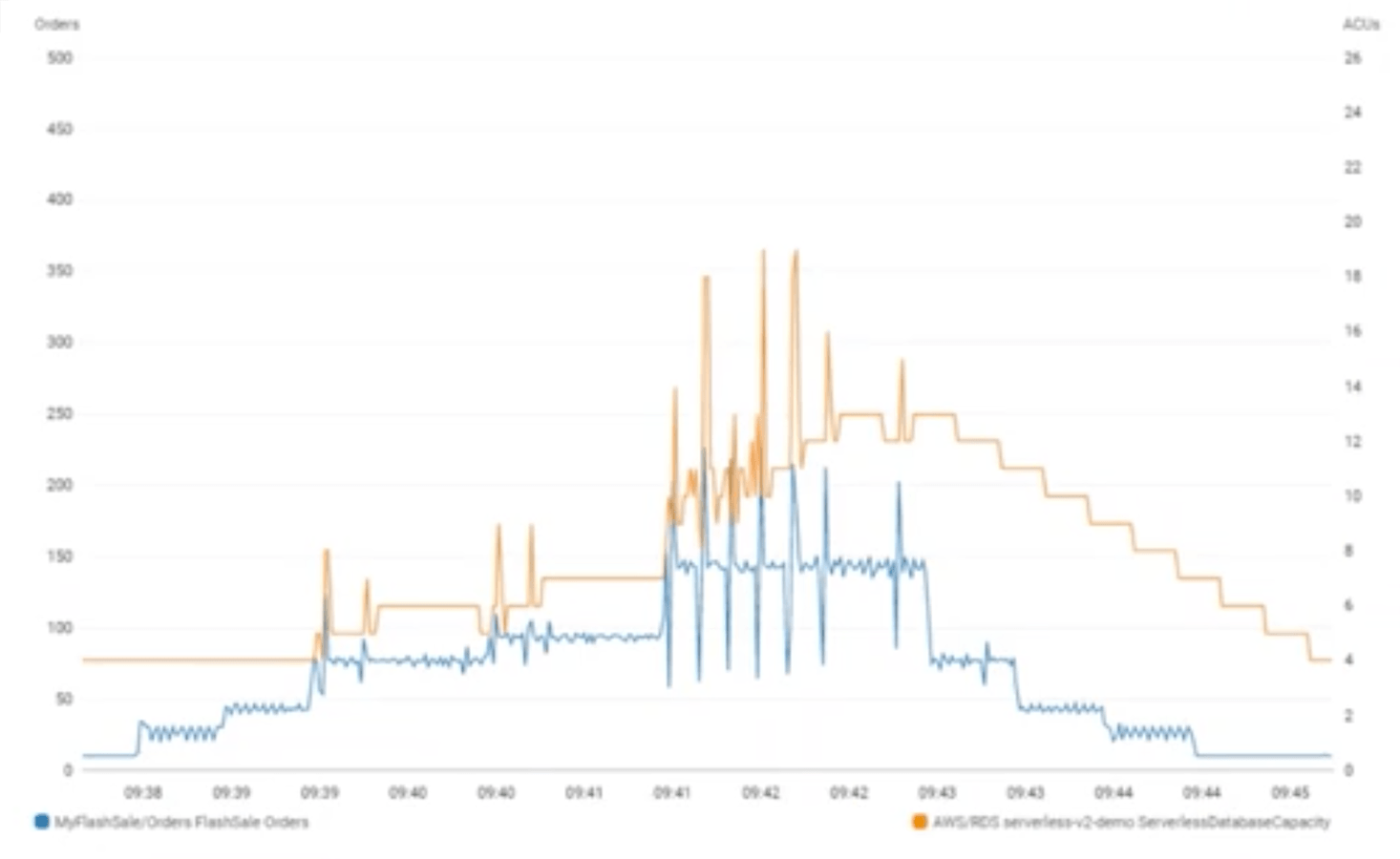
Update December 3, 2020: The presentation also ran a demo that showed the scaling capabilities of Aurora Serverless v2. The graph below shows the traffic (in blue) and the ACUs (in orange) instantly scaling to handle the load. Then you can see the step down scaling similar to my experiments.
Final Thoughts
Aurora Serverless v2 is still very early, and there is a long way to go before it's GA and it "supports the full breadth of Aurora features." Right now there are some very noticeable omissions, including the Data API and the pause capacity feature. However, assuming that the majority of features are added in by GA, the scaling performance turns this thing up to an 11. I'll be curious to see how the pricing works out, but given the fact that this almost entirely removes the need for capacity planning and significantly reduces the amount of database management, the total cost of ownership comparison could be very compelling.
I'm going to keep my eye on this one, because if it delivers on its promise, then auto-scaling, relational databases in the cloud might just be another solved problem.
I'd love to hear your feedback and thoughts on this new version!